

Pour avoir un tableur, il faut utiliser le menu Edit, puis Ajouter,
puis Tableur,statistiques ou le raccourci Alt+t.
On vous demande un nom, pour la sauvegarde ultérieure de ce tableur.
C’est ce nom de variable qui servira à sauver la matrice définie par le
tableur et c’est ce nom suivi du suffixe .tab qui sera de nom du fichier
contenant le tableur et ses formules. Par exemple, si vous donnez comme nom
M, la variable M
contiendra la matrice définie par le tableur
et lorsque vous appuyez sur le bouton Save M.tab, le fichier M.tab
sera le fichier qui contiendra le tableur avec toutes ses
formules et que l’on pourra retrouver lors de séances ultérieures.
Attention
Si vous ne donnez pas de nom, le bouton Save ne sera pas visible et il le
deviendra si vous utilisez Table->Sauver tableur comme du texte et vous
donnez, par exemple,comme nom M.
Si le contenu du tableur change, la matrice M change sans
avoir besoin de sauver, par contre le fichier M.tab ne changera que si
l’on sauve c’est à dire si on appuie sur Save M.tab.
On peut aussi sauver la sélection par exemple A0:C3 vers une variable
(menu Table), cette variable contiendra une matrice qui ne changera pas
même si le tableur change.
La Configuration generale du menu Configuration permet de
déterminer le nombre de lignes et de colonnes que l’on aura lors de
l’ouverture du tableur.
Dans un niveau contenant un tableur nous avons :
Le tableur est une feuille de calculs ayant la forme d’un tableau composé de
lignes et de colonnes qui déterminent des cases appelées cellules. Les
cellules contiennent des valeurs ou des commandes ou encore des formules
qui font références aux autres cellules.
Un éditeur de matrice a aussi la forme d’un tableau composé de
lignes et de colonnes qui déterminent des cases, mais ces cases ne peuvent
contenir que des scalaires.
Dans le menu Edit▸Configuration du tableur, l’item
Format permet d’avoir soit un tableur, soit un éditeur de matrice
permettant d’entrer facilement des matrices quelconques ou symétriques ou
etc...On a donc la possibilité lorsque l’on veut mettre dans le tableur une
matrice particulière (par exemple une matrice symétrique) de choisir de le
faire dans l’éditeur de matrice associé au tableur (on choisit par exemple
matrice symétrique dans Format), on entre la matrice
(les éléments symétriques sont mis automatiquement) puis, on repasse en
mode tableur en choisissant Tableur dans Format.
Le tableur est un tableau composé de colonnes désignées par
les lettres majuscules A,B,C,... et de lignes numérotées par
0,1,2,....
Les cases du tableur sont appelées cellules.
Ainsi, A0 désigne la première cellule du tableur.
L’éditeur de matrice est un tableau composé de lignes et de colonnes
numérotées par 0,1,2,...
Les cases de l’éditeur de matrice sont les éléments de la matrice.
Si on sauve la matrice en lui donnant comme nom M, M[0,1]
désigne la case située dans la ligne de numéro 0 et dans la colonne
de numéro 1.
Le menu Edit▸Configuration du tableur permet de
configurer le tableur (tableur se traduit en anglais par Spreadsheet).
Le tableur est une feuille de calculs ayant la forme d’un tableau composé de
lignes et de colonnes. Lorsqu’on a choisit Recalculer automatiquement
dans le menu Edit▸Configuration du tableur,
les cases ou cellules sont mises à jour automatiquement lorsque l’on modifie
une des cases et sinon il faut utiliser le bouton eval ou utiliser dans
le menu Edit▸Configuration du tableur, la commande
Evaluer le tableur (à exécution directe) ou encore utiliser le
raccourci clavier en appuyant sur F9.
L’item Format de ce menu configuration permet d’avoir soit un tableur,
soit un éditeur de matrice permettant d’entrer facilement des matrices
quelconques ou symétriques ou etc..
On peut préciser le nombre de lignes et de colonnes avec lesquelles on veut
travailler : par exemple pour entrer une matrice symétrique il faut avoir le
même nombre de lignes et de colonnes, on change ce nombre avec les items
Changer le nombre de lignes et Changer le nombre de colonnes dans
le menu Edit▸ Configuration du tableur.
On pourra bien sûr modifier ces nombres au cours du travail, par
exemple en utilisant le menu :
Edit▸Configuration▸Ajouter/effacer du tableur ou en utilisant la case de sélection (si on met G50
dans cette case, il y aura alors création d’un nombre suffisant de
lignes et de colonnes pour pouvoir sélectionner G50)
Toutes les fonctions (même graphiques) de Xcas sont utilisables dans le
tableur.
Le bouton STOP permet d’interrompre un calcul trop long.
La case de sélection est la case située en dessous du menu
Table.
La case de sélection est une case interactive :
- elle permet de connaitre le nom de la (ou des) cellule(s) sélectionnée(s)
avec la souris (si on sélectionne A3, A3 se note automatiquement dans cette case, si on sélectionne A2,A3,A4,B2,B3,B4, A2:B4 se note automatiquement dans cette case),
- elle permet aussi d’aller directement sur une cellule dont on spécifie le
nom : en effet lorsqu’on appuie sur cette case le curseur apparait, et on peut
remplacer, par exemple, A3 par A30 : les lignes (et les colonnes)
nécessaires sont créées et la cellule A30 se trouve
sélectionnée.
- elle permet aussi de sélectionner une ou plusieurs colonnes, par exemple,
en tapant dans cette case A0:C9 ou A0..C9 cela sélectionnera
les 10 premières lignes des colonnes A,B et C ou encore
en tapant dans cette case A0..9,C cela sélectionnera les 10
premières lignes des colonnes A et C. Grâce à cette case
de sélection on peut donc sélectionner des colonnes non contigües, ce que
l’on ne peut pas faire avec la souris.
Les différents boutons du tableur sont :
Le menu Fich est composé de :
On trouve dans ce menu :
Le menu Statistics ouvre pour chaque item une boite de dialogue où l’on
peut préciser : la sélection, la cellule cible (c’est dans cette cellule
que s’inscrira la commande choisie), si comme argument de la commande
choisie, on doit considérer les lignes ou les colonnes de la sélection et
si on doit mettre les valeurs ou les références de la sélection .
Voici les différents items du menu
Maths▸stats 1-d :
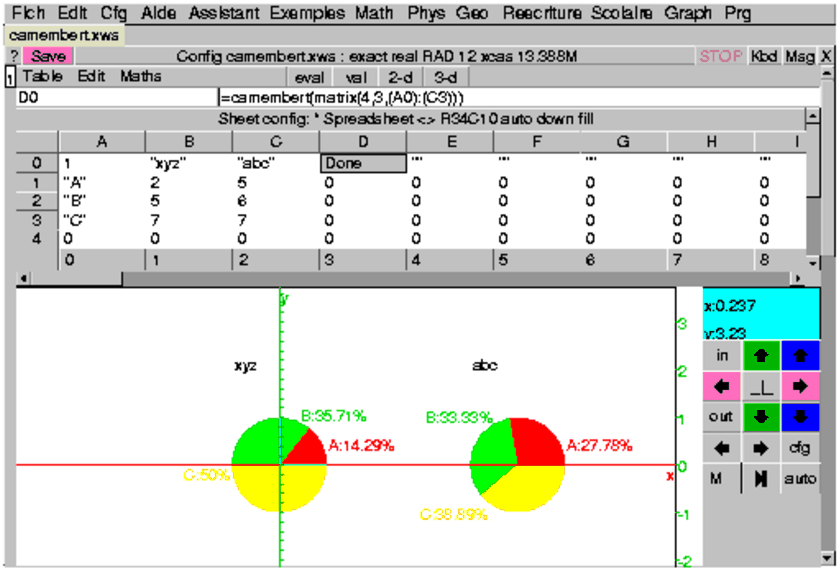
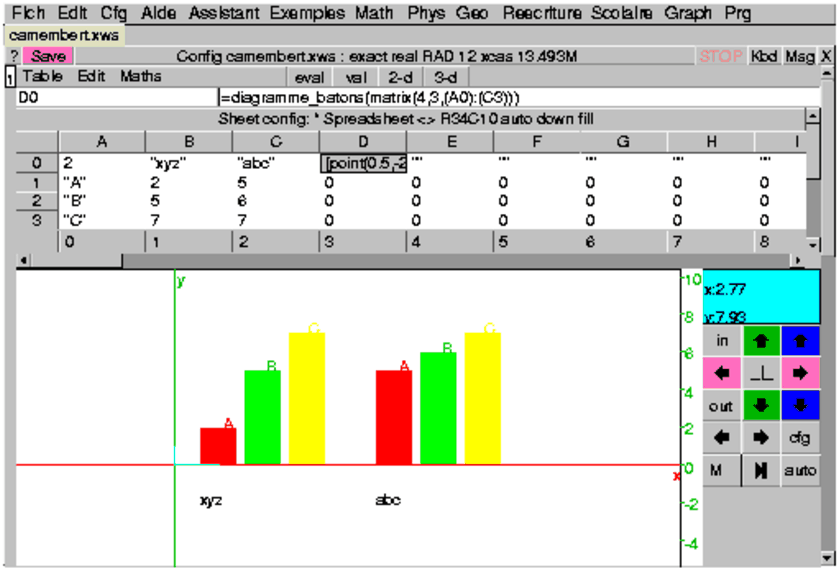

Le menu Maths▸stats 2-d contient les items suivants :
Dans une cellule on peut mettre :
Lorsqu’on consulte le tableur, toutes les cellules sont évaluées.
Pour voir le contenu évalué d’une cellule située hors du champ de vision,
on utilise, soit le curseur vertical (situé à droite du tableur) qui permet
de voir les dernières lignes, soit le curseur horizontal (situé à la
dernière ligne du tableur) qui permet de voir les dernières colonnes.
Remarque
Lorsque toutes les cellules sont visibles, ces deux curseurs ne sont pas
présents.
Pour voir le contenu non évalué d’une cellule (c’est à dire ce que l’on
a mis, initialement, dans la cellule comme formule ou comme valeur),
il suffit de cliquer sur
cette cellule : il apparait alors dans la ligne de commande la formule (ou
la valeur) qui a été mise dans cette cellule.
Pour faire apparaitre dans la ligne de commande, le contenu évalué de
la cellule, il suffit d’appuyer sur le bouton eval.
Lorsque le résultat est trop grand (ou trop petit) en taille on peut avoir
besoin d’agrandir une colonne pour voir ce résultat entièrement (ou de
diminuer la colonne pour gagner de la place). Par exemple, on veut modifier
la taille de la colonne B, on
déplace la souris sur le trait vertical qui sépare B de C :
le curseur devient ↔. On clique avec la souris et, sans
relacher le bouton de la souris, on déplace ce trait vertical pour agrandir
ou diminuer la largeur de la colonne B.
Lorsque le résultat est trop grand, on peut aussi appuyer sur le bouton
eval pour faire apparaitre ce résultat dans la ligne de commande.
Dans une cellule on peut mettre :
- une chaine de caractères,
- une expression algébrique,
- une formule faisant référence à d’autres cellules. Ces références
peuvent être absolues ou relatives à la cellule qui contient la formule.
Les références absolues sont obtenues en rajoutant $ devant la
lettre désignant la colonne ou devant le numéro de la ligne de la cellule
référence.
Les références relatives permettent de désigner les cellules par
rapport à une autre : ainsi A0 mis dans la cellule B1 désigne
la cellule située dans la colonne précédente et à la ligne
précédente et c’est cette information qui sera recopiée quand on
recopiera la formule vers le bas ou vers la droite.
Exemples :
Dans A0 il y a 1 et je tape dans B1 la formule :
Il y a deux façons de désigner un morceau du tableur selon que l’on veut
remplir une cellule ou le sélectionner dans la case de sélection.
Il sera désigné par :
Remarque
Dans la case de sélection, on ne peut pas utiliser "deux points"
(:) comme séparateur entre les deux références.
Exemple
Dans une cellule A0:B5 représente la liste des valeurs de
[A0,B0,A1,B1,..,A5,B5] constituée par la matrice "aplatie".
Dans la case de sélection, A0..B5 désigne le tableau de 6
lignes (lignes 0,1..5) et 2 colonnes (colonnes A et B).
On a aussi la possibilité de désigner dans la
case de sélection des colonnes non consécutives, on écrira par
exemple A0..10,C,E pour sélectionner
les 11 premières lignes des colonnes A, C et E.
Attention!!!
Seule la case de sélection permet de définir un
sous-tableau ou une matrice.
Donc dans une cellule pour désigner un sous-tableau on peut reconstituer la
matrice à l’aide de la commande list2mat (qui transforme une liste en
matrice selon le nombre de colonnes spécifié) si les colonnes sont
consécutives ou en utilisant la commande
tran (qui transforme une matrice en sa transposée).
Dans la cellule F0 on tape par exemple :
=list2mat(A0:B5,2) pour avoir une matrice avec 2 colonnes et 6 lignes
Dans la cellule F0 on tape par exemple :
=list2mat(A0:D5,4) pour avoir une matrice avec 4 colonnes et 6
lignes dans la cellule F0.
Dans la cellule F0 on tape par exemple :
=tran([A0:A3,C0:C3]) pour avoir une matrice avec 2 colonnes et 4
lignes dans la cellule F0.
Dans la cellule F0 on tape par exemple :
=tran([A0:A3,B0:B3,C0:C3]) pour avoir une matrice avec 3 colonnes et 4
lignes dans la cellule F0.
Attention!!!
On ne peut pas remplir plusieurs cellules d’un seul coup avec une matrice
contenant des références à d’autres cellules : quand il y a une formule
faisant des références à d’autres cellules on ne peut remplir qu’une
seule cellule et il faut mettre le signe = devant la formule.
Vous avez rempli l’écran du tableur avec une matrice.
Pour sauver cette matrice vous pouvez utiliser le bouton Save de la barre de boutons cela sauvera la matrice sous le nom inscrit dans la ligne d’état après Spreadsheet (en général le même nom que le nom du fichier sans son extension .tab ou vous pouvez utiliser le menu Fich sous-menu Nom de variable en donnant un autre nom de variable.
Pour sauver une sous-matrice, il faut la sélectionner soit avec la souris,
soit en utilisant la case de sélection et ensuite
utiliser le menu Fich sous-menu Sauver selection vers variable
puis donner le nom de la variable qui stockera la matrice sélectionnée
(cf 1.1.6).
La format est celui d’une matrice. On aura donc dans la variable designée
une matrice par exemple : [[1,2,3,4,5],[1,0,2,0,1],[...]]
Vous avez rempli un tableur avec différentes formules. Pour sauver ce
tableur il suffit d’utiliser le bouton sauver de la barre de boutons ou
on utilise le menu Fich sous-menu Sauver comme (cf 1.1.6).
Lorsque vous sauvez ainsi, vous sauvez à la fois les formules et les valeurs.
En effet, le format de sauvetage est une matrice dont chaque coefficient est
une liste de trois éléments : le premier élément est la formule qui
définit la cellule, le deuxième élément est la valeur prise par la
cellule et le troisième est une variable détat interne.
On aura par exemple spreadsheet[[[3,3,2],[=A0+1,4,2]],[...]],
cela vaut dire que A0=3, que B0=A0+1 et que la valeur de
B0 est 4.
Lors d’une évaluation du tableur, la troisième valeur vaut :
0 si la cellule n’a pas encore été recalculée,
1 si la cellule est en cours de calcul,
2 si la cellule a été calculée.
L’algorithme est le suivant :
1/ On fait toutes les cellules de la gauche vers la droite
et du haut vers le bas,
2/ Si le troisième argument de la cellule vaut 2, c’est fini.
Si le troisième argument de la cellule vaut 1, on envoie une erreur :
"évaluation récursive",
3/ le troisième argument de la cellule vaut 0, on le met à 1 et
on cherche toutes les cellules dépendant de cette cellule,
on calcule leurs valeurs et on remplace puis, on met à 2 le troisième
argument de la cellule.
Il faut sélectionner la cellule à recopier avec la
souris et se servir du bouton copier du tableur.
Puis, on met le curseur dans une ligne d’enrée, puis on appuie sur la touche
coller, et la cellule est recopiée dans la ligne de commande.
Si les cellules sont consécutives, on peut les sélectionner avec la
souris, sinon on utilisera la case de sélection.
On tape par exemple dans la case de sélection :
A0..3,D
les quatre premières cellules des colonnes A et D sont alors
sélectionnées.
Puis, on met le curseur dans une ligne de commande et on appuie sur la touche
coller, et les quatre
premières cellules des colonnes A et D sont recopiées dans la
ligne de commande.
On peut avoir, dans le tableur, le tableau des valeurs numériques d’une
expression f(x) pour x=x0, x0+h, x0+2*h.... en tapant dans la ligne
de commande du tableur :
tablefunc(f(x),x,x0,h) ou tablefunc(f(x),x).
Après avoir selectionné A0, on tape, par exemple, dans la ligne de
commande du tableur :
^2,x,-1,0.2)
On obtient si on a 15 lignes :
| A | B | |
| 0 | x | x2 |
| 1 | 0.2.0 | "Tablefunc" |
| 2 | -1 | 1.0 |
| 3 | -0.8 | 0.64 |
| 4 | -0.6 | 0.36 |
| .. | .. | .. |
| 14 | 1.4 | 1.96 |
Dans le cas où les valeurs du point de départ x0 et du pas h ne
sont pas précisées, ces valeurs valent par défaut x0=X- et
h=((X+)-(X-))/10 où X- et X+ sont définis dans la
configuration du graphique (bouton rouge geo) et valent au démarrage
X-=-5.0 et X+=5.0 et donc x0=-5.0 et h=1.0.
On peut donc avoir aussi dans le tableur, les valeurs numériques des termes
d’une suite un=f(n) pour n=n0, n0+1, n0+2,.... en tapant dans la
ligne de commande du tableur :
tablefunc(f(n),n,n0).
Après avoir selectionné A0, on tape, par exemple, dans la ligne de
commande du tableur :
^2,n,5,1)
On obtient si on a 15 lignes :
| A | B | |
| 0 | n | n2 |
| 1 | 1.0 | "Tablefunc" |
| 2 | 5 | 25.0 |
| 3 | 6.0 | 36.0 |
| 4 | 7.0 | 49.0 |
| .. | .. | .. |
| 14 | 17.0 | 289.0 |
Remarque
Lorsque la colonne A est sélectionnée, tablefunc(f(x),x,x0,h)
a pour effet de placer, dans la colonne A et à partir de la ligne
0 :
x,h,x0,A2+A$1 et,
dans la colonne B et à partir de la ligne 0 :
f(x),"Tablefunc",evalf(subst(B$0,A$0,A2))
On peut avoir, dans le tableur, les valeurs numériques des termes d’une suite
récurrente (u0=u0, un=f(un-1)) grâce à la commande :
tableseq(f(n),n,u0).
Après avoir selectionné A0, on tape, par exemple, dans la ligne de
commande du tableur :
On obtient, si on a 7 lignes :
| A | |
| 0 | 0.5*(n+3/n) |
| 1 | n |
| 2 | 3 |
| 3 | 2 |
| 4 | 1.75 |
| .. | .. |
| 7 | 1.73205080757 |
Après avoir selectionné B0, on tape, par exemple, dans la ligne de commande du tableur :
On obtient, les premiers termes de la suite de Fibonacci :
| B | |
| x+y | |
| 1 | x |
| 2 | y |
| 3 | 1 |
| 4 | 1 |
| 5 | 2 |
| .. | .. |
| 7 | 5 |
| .. | .. |
Remarque
Lorsque la colonne E est sélectionnée,
tableseq(f(n),n,u0) a pour effet de placer,
dans la colonne E et à partir de la ligne 0 :
f(n),n,u0,evalf(subst(E$0,E$1,E2)).
Row et Col sont des fonctions qui sont utilisables essentiellement
dans le tableur, en dehors du tableur Row et Col sont le numéro
de la ligne et de la colonne de la cellule sélectionnée du dernier tableur
évalué.
Row n’a pas des paramètre et renvoie le numéro de la ligne
de la cellule courrante.
On tape quand la cellule C4 est mise en surbrillance :
Row()
On obtient :
4
Col n’a pas des paramètre et renvoie le numéro de la colonne
de la cellule courrante (la colonne A a pour numéro 0,
la colonne B a pour numéro 1 etc...)
On tape quand la cellule C4 est mise en surbrillance :
Col()
On obtient :
3
Ainsi si dans la cellule A0 je mets :
=Row()+Col()
puis je recopie cette formule vers le bas et j’obtiens :
dans la colonne A :
0,1,2,3,4...
puis je recopie cette formule vers la droite depuis A0 et j’obtiens :
dans la ligne 0 :
0,1,2,3,4...
puis je recopie cette formule vers la droite depuis A1 et j’obtiens :
dans la ligne 1 :
1,2,3,4,5... etc...
Attention Bien mettre le signe = car Row() et Col()
font références à la ligne et à la colonne de la cellule dans laquelle
se trouve la formule.
current_sheet est une fonction qui est utilisable
essentiellement dans le tableur, en dehors du tableur current_sheet
permet d’avoir accès aux cellules du dernier tableur évalué.
current_sheet s’utilise soit avec :
- aucun paramètre : current_sheet() renvoie le tableur tout entier,
- un paramètre entier : current_sheet(j) renvoie la ligne j
du tableur,
- deux paramètres entiers : current_sheet(j,k) renvoie la cellule du
tableur située à la ligne j et à la colonne k.
Ainsi current_sheet(3,1) désigne la cellule B3.
Cela permet de désigner une cellule par deux variables entières,
par exemple :
j:=3;k:=1;current_sheet(j,k)
Remarque
Pour avoir la colonne k du tableur dans une ligne de commande, il faut
taper :
tran(current_sheet())[k] (puisque tran(current_sheet())
désigne la transposée du tableur).
On peut bien sûr utiliser current_sheet dans le tableur.
On tape :
=current_sheet(1,2)
ou encore, on peut prendre la valeur d’une case comme indice :
si A0 contient 1 et B1 contient 2 on peut taper,
=current_sheet(A0,B1).
Exemple d’utilisation :
On tape la suite des nombres entiers dans la colonne A.
On tape dans A0 :
1
puis on tape dans A1 :
=A0+1
formule que l’on recopie avec avec le menu
Edit du tableur, puis, Remplir et Copier vers le bas.
Dans la colonne B on met, par exemple, la suite
un=∑k=0n(−1)k/(k+1).
On tape dans B0 :
1
puis on tape dans B1 :
=B0+(-1)^A1/(A1+1), formule que l’on recopie avec le menu
Edit du tableur, puis, Remplir et Copier vers le bas.
On veut extraire de cette suite, les termes d’indice pair dans la colonne
C, on tape dans C0 :
=current_sheet(2*A0,1), formule que l’on recopie
avec remplir et vers le bas.
On veut extraire de cette suite les termes d’indice impair dans la colonne
D, on tape dans D0 :
=current_sheet(2*A0+1,1), formule que l’on recopie avec le menu
Edit du tableur, puis, Remplir et Copier vers le bas.
Ou encore on utilise Row et on n’a besoin que de 3 colonnes .
On tape dans A0 :
1
puis on tape dans A1 :
=A0+(-1)^Row()/(Row()+1), formule que l’on recopie avec le menu
Edit du tableur, puis, Remplir et Copier vers le bas.
On veut extraire de cette suite, les termes d’indice pair dans la colonne
B, on tape dans B0 :
=current_sheet(2*Row(),0), formule que l’on recopie
avec remplir et vers le bas.
On veut extraire de cette suite les termes d’indice impair dans la colonne
C, on tape dans C0 :
=current_sheet(2*Row()+1,0), formule que l’on recopie avec le menu
Edit du tableur, puis, Remplir et Copier vers le bas.
On suppose que dans la colonne A il y a 1,2,3,4, dans la colonne
B il y a 2,4,6,8 et dans la colonne C il y a
4,8,12,16.
Attention !
Pour désigner une plage du tableur, on tape A0:C3, mais Xcas le
raplatit en une liste : dans l’exemple ci-dessus A0:C3=[1,2,2,4,3,6]
Remarque
Pour avoir une méthode rapide pour compter, par exemple, les sommes obtenues
lorsqu’on lance 101 fois deux dés. On remplit aléatoirement les colonnes
A et B en tapant ranm(101,1) comme valeur pour A0 et
B0.
Il faut créer une cellule tampon, qui contiendra le tableau des
valeurs de la zone à analyser. On place simplement dans
cette cellule la definition de la plage précédée de =, par exemple
si A0 à B100 contient des jets de deux dés, et que
C contient la somme de la colonne A et de la colonne B,
on met dans D0 : = C0:C100.
Ensuite dans D2 à D12 on ecrit :
=count_eq(2,D0)... count_eq(12,D0)
Ainsi le calcul de la plage C0:C100 qui est long n’est fait qu’une
fois. C’est le meme principe qu’en programmation, on utilise une
variable intermediaire (la cellule tampon D0).
count a deux ou trois paramètres : une fonction réelle
f et une liste ou un sous-tableau éventuellement un paramètre
optionnel row ou col.
Attention dans le tableur les paramètre optionnels row ou
col ne servent pas, car dans une ligne du tableur
un sous-tableau (par exemple A0:C3) désigne une liste : en effet
si dans une cellule on met =A0:C3, la cellule contient la liste obtenue
en mettant les lignes du sous tableau A0:C3 bout à bout.
Si vous voulez utiliser le sous tableau (par exemple A0:C3) comme une
matrice il faut mettre dans une cellule =list2mat(A0:C3),3) (car 3
est le nombre de colonnes de A0:C3). On peut aussi sauver la sélection
A0:C3 vers une variable (menu Table), car lors de cette affectation
la matrice n’est pas aplati et donc cette variable contient une matrice.
count applique la fonction aux éléments de la
liste ou du sous-tableau et en renvoie la somme.
Si f est une fonction boolénne count renvoie le nombre
d’éléments de la liste ou du sous-tableau pour lesquels la fonction
boolénne est vraie.
On tape dans une cellule :
On obtient :
En effet, la somme des éléments de A0:C3 vaut (1+2+3+4)*7=70
car dans A il y a 1,2,3,4 dans B il y a 2*A soit 2,4,6,8 et dans C il y a 4*A
soit 4,8,12,16 donc en tout il y a 7*A.
On tape dans une cellule :
On obtient :
En effet, il y a 6,8,8, soit 3 éléments qui sont entre 5 et 10.
count_eq a deux ou trois paramètres : une nombre et une liste
réelle ou un sous-tableau et éventuellement un paramètre
optionnel row ou col.
Attention dans le tableur les paramètre optionnels row ou
col ne servent pas, car dans le tableur car un sous-tableau est aplati en
une liste.
count_eq renvoie le nombre d’éléments de la liste ou du sous-tableau
qui sont égaux au premier argument.
On tape dans une cellule :
On obtient :
car dans A il y a 1,2,3,4 dans B il y a 2*A soit 2,4,6,8 et dans C il y a 4*A soit 4,8,12,16.
count_inf a deux ou deux paramètres : une nombre et une liste
réelle ou un sous-tableau et éventuellement un paramètre
optionnel row ou col.
Attention dans le tableur les paramètre optionnels row ou
col ne servent pas, car dans le tableur car un sous-tableau est aplati en
une liste.
count_inf renvoie le nombre d’éléments de la liste (ou du
sous-tableau qui sont strictement inférieurs au premier argument.
On tape dans une cellule :
On obtient :
car dans A il y a 1,2,3,4 dans B il y a 2*A soit 2,4,6,8 et dans C il y a 4*A soit 4,8,12,16.
count_sup a deux ou trois paramètres : une nombre et une
liste réelle ou un sous-tableau et éventuellement un paramètre
optionnel row ou col.
Attention dans le tableur les paramètre optionnels row ou
col ne servent pas, car dans le tableur car un sous-tableau est aplati en
une liste.
count_sup renvoie le nombre d’éléments de la liste
ou du sous-tableau qui sont strictement supérieurs au premier argument.
On tape dans une cellule :
On obtient :
car dans A il y a 1,2,3,4 dans B il y a 2*A soit 2,4,6,8 et dans C il y a 4*A soit 4,8,12,16.
On peut utiliser directement le graphique depuis le tableur : les fonctions
graphiques peuvent être utilisées dans une cellule. Pour avoir
l’histogramme, la boite à moustaches, un nuage de points ou une ligne
polygonale depuis le tableur on peut se servir du menu Maths du
tableur (puis stats 1-d) après avoir sélectionné dans le
tableur l’argument avec la souris ou avec la case de sélection.
Dans ce cas, une boite de dialogue s’ouvre, vous devez choisir la cellule cible
(c’est dans cette cellule que s’inscrira la commande graphique), vous pouvez
éventuellement modifier la sélection (en mettant par exemple A1..B6
dans cellules entrée), vous pouvez cocher (resp ne pas cocher)
valeur pour que la commande graphique ait pour argument les valeurs
(resp les références) de la sélection : donc si valeur n’est pas
cochée un changement de valeur dans une cellule de la sélection aura pour
conséquence un changement du graphique, si on est en mode automatique ou si
on appuie sur le bouton eval.
Ou encore, on peut taper la commande correspondante (ou se servir du menu
Math▸Proba_stats▸1-d) dans la
ligne de commande du tableur en recopiant les arguments en se servant de la
souris (ou en se servant de la case de sélection et de la touche
coller lorsque les colonnes que l’on veut recopier ne sont pas
consécutives), ou encore on peut sauver la sélection dans une variable en
utilisant le menu du tableur
Table▸Sauver sélection vers variable on
donne un nom par exemple A, puis on tape moustache(A) ou... Dans ce
cas on travaille avec les valeurs de la sélection.
interval2center a comme argument un intervalle ou une liste
(resp séquence) d’intervalles (utile pour définir les centres des classes).
interval2center renvoie le centre de l’intervalle ou la liste
(resp séquence) des centres de ces intervalles.
interval2center est utile pour définir les centres des classes.
On tape :
On obtient :
On tape :
On obtient :
center2interval a comme argument un vecteur de réels V
d’au moins deux composantes et éventuellement un réel comme deuxième
argument.
center2interval renvoie un vecteur d’intervalles ayant pour centres
les composantes de l’argument V : ces intervalles sont définis en
commençant le premier intervalle, par le deuxième argument ou à
défaut par (3*V[0]-V[1])/2.
center2interval est utile pour définir des classes à partir de leurs
centres et du minimum des classes.
On tape :
Ou on tape car la valeur par défaut du deuxième argument est 2=(3*3-5)/2 :
On obtient :
On tape :
On obtient :
Attention
On ne peut pas mettre n’importe quoi comme deuxème argument!!!
On tape :
Ou on tape, car la valeur par défaut du deuxième argument est 4=(3*5-7)/2 :
On obtient :
La fonction suivante peut vous permettre de trouver l’intervalle dans lequel
il faut choisir le deuxème argument, quand il y a une solution!!!
En effet on doit pouvoir trouver a0,a1,a2... vérifiant :
a0<a1<a2.... et
a0+a1=2*c0=b0,a1+a2=2*c1=b1,a2+a3=2*c2=b2.... quand L=[c0,c1,c2...] avec
c0<c1<c2....
On a donc :
a1=b0−a0,
a2=b1−a1=b1−b0+a0,
a3=b2−a2=b2−b1+b0−a0
a4=b3−a3 ...
comme on doit avoir a0<a1 et a1<a2 (c’est à dire a1<c1) il faut donc
trouver a0 vérifiant a0<c0 et b0−c1<a0 puis
a2<a3 i.e. a0<c2−c1+c0 et
a3<a4 i.e.a3<c3 b0−b1+b2−c3<a0...
On construit donc deux listes :
l1=[c0,c2-2*c1+2*c0...] et
l2=[2*c0-c1,2*c0-2*c1+2*c2-c3,..].
La condition que doit vérifier a0 est alors :
max(l1)<a0<min(l2).
debut_classes(L):={
local l1,l2, n,j, a, b;
n:=size(L);
L:=sort(L);
l1:=[L[0]];
l2:=[2*L[0]-L[1]];
for (j:=1;2*j+1<n;j++) {
l1:=concat(l1,l2[j-1]-L[2*j-1]+L[2*j]);
l2:=concat(l2,l1[j]+L[2*j]-L[2*j+1]);
}
if (irem(n,2)==1) {
j:=quo(n-1,2);
l1:=concat(l1,l2[j-1]-L[2*j-1]+L[2*j]);
}
a:=max(l2);
b:=min(l1);
if (a<b) return(]a,b[); else return ("impossible");
}
On tape :
On obtient :
On tape :
On obtient :
On tape :
On obtient :
La commande sum permet de calculer la somme des éléments d’une
liste.
Si on a une matrice ou un sous-tableau définie dans un tableur, on sait
qu’en désignant ses éléments par :
"référence de la première case de la matrice" :
"référence de sa dernière case de la matrice", on obtient la liste des
éléments de la matrice (par ex A0:B1 est la liste [A0,B0,A1,B1]
formée par la matrice aplatie).
Attention
Pour traiter les exemples qui suivront, on remplit par exemple la colonne
A par 0,1,2,..,n et la colonne
B par 0,1,4,..,n^2.
Pour cela on met 0 dans A0, et
=A0^2 dans B0, =A0+1 dans A1 puis on utilise le
bouton remplir et vers le bas pour recopier les 2 formules dans
chacune des colonnes
A et B.
Après avoir selectionné C0, on tape, par exemple, dans la ligne de
commande du tableur :
On obtient dans C0 :
en effet : 1+2+3+4+5+1+4+9+16+25=3*5+5*11=70
Mais dans une ligne d’entrée, si on tape :
sum([[0,0],[1,1],[2,4],[3,9],[4,16],[5,25]])
On obtient :
[15,55]
qui est la somme des colonnes de la matrice.
Après avoir selectionné D0, on tape, par exemple, dans la ligne de
commande du tableur :
On obtient dans D0:
en effet : 1+2+3+4+5+1+4+9+16+25+64=3*5+5*11+64=134
On tape dans D1 :
On obtient dans D1 la somme des cellules B1 à B10 :
En effet current_sheet(j,1) désigne la cellule de la colonne B (colonne 1) et de la ligne j et puisque j varie de 1 à D0 qui vaut 10, donc dans D1 on a la somme des cellules de B1 à B10.
Si mean a comme argument une liste, mean calcule la
moyenne des éléments de cette liste.
Si mean a comme argument deux listes, mean calcule la
moyenne des éléments de la première listes, pondérés par les
éléments de la seconde liste.
Pour traiter les exemples, on remplit la colonne A par
0,1,2,..,n et la colonne
B par 0,1,4,..,n^2 (cf 1.10.4)
Remarque
Une cellule remplie avec une chaine de caractères vide n’est pas prise en
compte : on peut ainsi faire les calculs sur les réponses effectives à un
questionnaire, par exemple, et ainsi de ne pas tenir compte des questionnaires
non complètement remplis.
La commande mean permet de calculer la moyenne de plusieurs cellules
situées dans un sous-tableau.
Après avoir selectionné C0, on tape, par exemple, dans la ligne de
commande du tableur :
On obtient dans C0 :
en effet : A0:B5 désigne la liste [0,0,1,1,2,4...,5,25]
mean(A0:B5) renvoie donc la valeur de :
(1+2+3+4+5+1+4+9+16+25)/12=70/12=35/6=5.83333333333.
Mais dans une ligne d’entrée, si on tape :
mean([[0,0],[1,1],[2,4],[3,9],[4,16],[5,25]])
On obtient :
[5/2,55/6]
La commande mean permet de calculer la moyenne des valeurs de cellules
situées dans un sous-tableau pondérée par un autre sous-tableau.
Après avoir selectionné D0, on tape, par exemple, dans la ligne de
commande du tableur :
On obtient dans D0 :
en effet, mean(A3:B5,A0:B2) calcule :
(4*1+5*2+16*1+25*4)/(1+2+1+4)=130/8=65/4.
Mais dans une ligne d’entrée, si on tape :
mean([[3,9],[4,16],[5,25]],[[0,0],[1,1],[2,4]])
On obtient :
[14/3,116/5]
En effet :
mean([3,4,5],[0,1,2])=14/3
mean([9,16,25],[0,1,4])=116/5
ce sont les moyennes des colonnes du premier argument pondérée par les
colonnes du deuxième argument.
Après avoir selectionné D0, on tape, par exemple, dans la ligne de
commande du tableur :
On obtient dans D0 :
en effet, mean(A0:A5,B0:B5) calcule :
(1*1+2*4+3*9+4*16+5*25)/(1+4+9+16+25)=45/11.
Il y a deux cas :
Si stddev a comme argument une liste, stddev
calcule l’écart-type des éléments de ce sous-tableau.
Si stddev a comme argument deux listes, stddev calcule
l’écart-type des éléments de la première liste, pondérés par les
éléments de la seconde liste.
Pour traiter les exemples, on remplit la colonne A par
0,1,2,..,n et la colonne
B par 0,1,4,..,n^2 (cf 1.10.4)
La commande stddev permet de calculer l’écart type des valeurs de
cellules situées dans un sous-tableau.
Après avoir selectionné C1, on tape, par exemple, dans la ligne de
commande du tableur :
On obtient dans C1 :
Mais dans une ligne d’entrée, si on tape :
stddev([[0,0],[1,1],[2,4],[3,9],[4,16],[5,25]])
On obtient :
[sqrt(35/12),sqrt(2849/36)]
La commande stddev permet de calculer l’écart-type des valeurs de
cellules situées dans un sous-tableau pondérées par un autre sous-tableau.
Après avoir selectionné D1, on tape, par exemple, dans la ligne de
commande du tableur :
On obtient dans D1 :
Mais dans une ligne d’entrée, si on tape :
stddev([3,9],[4,16],[5,25]],[[0,0],[1,1],[2,4]])
On obtient :
[sqrt(2/9),sqrt(324/25)]
stdDev a les mêmes arguments que stddev.
Si le premier argument a comme dimension n, on a la relation :
n:=size(L);stdDev(L)=stddev(L)*sqrt(n/(n-1))
La commande stdDev permet de calculer une estimation de l’écart-type de
la population mère à partir d’un échantillon d’ordre n et dont les
valeurs sont mises en argument.
Après avoir selectionné C2, on tape, par exemple, dans la ligne de
commande du tableur :
On obtient dans C2 :
ici n=6*2=12 et 12/11*1877/36=1877/33 Après avoir selectionné D2, on tape, par exemple, dans la ligne de commande du tableur :
On obtient dans D2 :
ici n=8 et 8/7*1419/16=1419/14
Il y a deux cas :
Si variance a comme argument une liste, variance calcule la
variance des éléments de cette liste.
Si variance a comme argument deux listes, variance calcule
la variance des éléments de la première liste, pondérés par les
éléments de la seconde liste. La variance est le carré de
l’écart-type.
Pour traiter les exemples, on remplit la colonne A par
0,1,2,..,n et la colonne
B par 0,1,4,..,n^2 (cf 1.10.4).
La commande variance permet de calculer la variance des valeurs de
cellules situées dans un sous-tableau.
Après avoir selectionné C2, on tape, par exemple, dans la ligne de
commande du tableur :
On obtient dans C2 :
La commande variance permet de calculer la variance des valeurs de
cellules
situées dans un sous-tableau pondérée par un autre sous-tableau.
Après avoir selectionné D2, on tape, par exemple, dans la ligne de
commande du tableur :
On obtient dans C6 :
Il y a deux cas :
Si median a comme argument une liste, median calcule la
médiane des éléments de cette liste.
Si median a comme argument deux listes, median calcule la
médiane des éléments de la première liste, pondérée par les
éléments de la seconde liste.
La médiane est l’élement Me de la série
à partir du lequel la fréquence cumulée de Me égale ou dépasse
0.5 (on appelle fréquence cumulée d’une valeur a la somme des
fréquences de t pour toutes les valeurs t ≤ a)
Un sous-tableau est transformé en une liste quand on le désigne dans
un tableur par :
"référence de sa première case" :
"référence de sa dernière case".
Pour traiter les exemples, on remplit la colonne A par
0,1,2,..,n et la colonne
B par 0,1,4,..,n^2 (cf 1.10.4).
La commande median permet de calculer la médiane des valeurs de
cellules situées dans un sous-tableau.
Après avoir selectionné C3, on tape, par exemple, dans la ligne de
commande du tableur :
On obtient dans C3 :
La commande median permet de calculer la médiane des valeurs de
cellules
situées dans un sous-tableau pondérée par un autre sous-tableau.
Après avoir selectionné D3, on tape, par exemple, dans la ligne de
commande du tableur :
On obtient dans C7 :
Il y a deux cas :
Si quartile1 a comme argument un sous tableau, quartile1 calcule le
premier quartile des éléments de ce sous-tableau.
Si quartile1 a comme argument deux sous tableaux, quartile1 calcule
le premier quartile des éléments du premier sous-tableau, pondérés par
les éléments du second sous-tableau.
Le premier quartile est l’élement
Q1 de la série à partir du lequel la fréquence cumulée de Q1
égale ou dépasse 0.25.
Pour traiter les exemples, on remplit la colonne A par
0,1,2,..,n et la colonne
B par 0,1,4,..,n^2 (cf 1.10.4).
La commande quartile1 permet de calculer le premier quartile
des valeurs de
cellules situées dans un sous-tableau.
Après avoir selectionné C4, on tape, par exemple, dans la ligne de
commande du tableur :
On obtient dans C4 :
La commande quartile1 permet de calculer le premier quartile des valeurs
de cellules
situées dans un sous-tableau pondérée par un autre sous-tableau.
Après avoir selectionné D4, on tape, par exemple, dans la ligne de
commande du tableur :
On obtient dans D4 :
Il y a deux cas :
Si quartile3 a comme argument un sous tableau, quartile3 calcule le
troisième quartile des éléments de ce sous-tableau.
Si quartile3 a comme argument deux sous tableaux, quartile3 calcule
le troisième quartile des éléments du premier sous-tableau,
pondérés par les éléments du second sous-tableau. Le troisième
quartile est l’élement Q3 de la série à partir du lequel la
fréquence cumulée de Q3 égale ou dépasse 0.75.
Pour traiter les exemples, on remplit la colonne A par
0,1,2,..,n et la colonne
B par 0,1,4,..,n^2 (cf 1.10.4).
La commande quartile3 permet de calculer le troisième quartile
des valeurs de cellules situées dans un sous-tableau.
Après avoir selectionné C5, on tape, par exemple, dans la ligne de
commande du tableur :
On obtient dans C5 :
La commande quartile3 permet de calculer le troisième quartile
des valeurs de cellules situées dans un sous-tableau pondérées par un
autre sous-tableau.
Après avoir selectionné D5, on tape, par exemple, dans la ligne de
commande du tableur :
On obtient dans D5 :
Il y a deux cas :
Si quartiles a comme argument un sous tableau, quartiles calcule
la matrice colonne contenant le minimum, le premier quartile, la médiane,
le troisième quartile et le maximum des éléments de ce sous-tableau.
Si quartiles a comme argument deux sous tableaux, quartiles calcule
la matrice colonne contenant le minimum, le premier quartile, la médiane,
le troisième quartile et le maximum des éléments du premier sous-tableau,
pondérés par les éléments du second sous-tableau.
Pour traiter les exemples, on remplit la colonne A par
0,1,2,..,n et la colonne
B par 0,1,4,..,n^2 (cf 1.10.4).
La commande quartiles permet de calculer la matrice colonne contenant
le minimum, le premier quartile, la médiane, le troisième quartile et
le maximum des valeurs de cellules situées dans un sous-tableau.
Après avoir selectionné C6, on tape, par exemple, dans la ligne de
commande du tableur :
On obtient dans C6 :
La commande quartiles permet de calculer la matrice colonne contenant
le minimum, le premier quartile, la médiane, le troisième quartile et
le maximum des valeurs de cellules
situées dans un sous-tableau pondérées par un autre sous-tableau.
Après avoir selectionné D6, on tape, par exemple, dans la ligne de
commande du tableur :
On obtient dans D6 :
On peut utiliser directement le graphique depuis le tableur : toutes les
fonctions graphiques peuvent être utilisées dans une cellule. Pour avoir un
nuage de points on utilise scatterplot et pour tracer une ligne
polygonal on utilise polygonplot.
Depuis le tableur, on peut se servir du menu du tableur
Statistiques▸2-d et remplir la boite de dialogue
correspondant à l’item choisi : vous devez choisir la cellule cible (c’est
dans cette cellule que s’inscrira la commande graphique), vous pouvez
éventuellement modifier la sélection (en mettant par exemple A1..B6
dans cellules entrée), vous pouvez cocher (resp ne pas cocher)
valeur pour que la commande graphique ait pour argument les valeurs (resp
les références) de la sélection : donc si valeur n’est pas cochée
un changement de valeur dans une cellule de la sélection aura pour
conséquence un changement du graphique, si on est en mode automatique ou si
on appuie sur le bouton eval.
Ou bien, dans la ligne de commande du tableur ou dans une ligne de commande, on
utilise scatterplot et polygonplot du menu
Math▸Stats▸2-d et on recopie les
arguments en les sélectionnant, soit en se servant de la souris (ou de la
case de sélection et de la touche coller lorsque les colonnes
que l’on veut recopier ne sont pas consécutives), soit on sauve cette
sélection avec le menu du tableur Fich▸Sauver
sélection vers variable, on donne un nom par exemple A, puis on tape
polygonplot(A) ou scatterplot(A): dans ce cas on travaille avec les
valeurs de la sélection.
covariance calcule la covariance numérique de plusieurs cellules
situées dans deux sous-tableaux de même dimension.
Si T=tj est le premier argument et B=bj le
deuxième argument, la covariance covariance(T,B) est alors définie
par :
cov(T,B)=1/N∑j(tj−mT)(bj−mB)
où mT (resp mB) est la moyenne des éléments tj de T
(resp bj de B) et N le nombre d’éléments de T.
Pour traiter les exemples, on remplit la colonne A par
0,1,2,..,n et la colonne
B par 0,1,4,..,n^2 (cf 1.10.4).
On tape lorsque C0 est en surbrillance :
On obtient dans C0 :
Dans une ligne d’entrée, on tape :
Ou on tape :
On obtient :
correlation calcule la corrélation linéaire numérique de plusieurs
cellules situées dans deux sous-tableaux de même dimension.
Si T=tj est le premier argument et B=bj le
deuxième argument, la corrélation correlation(T,B) est alors :
cov(T,B)/σ(T) σ(B)
où σ(T) (resp σ(B)) est l’écart-type des
éléments de T (resp B) et cov(T,B) est la covariance de
T et de B.
Dans le tableur
Pour traiter les exemples, on remplit la colonne A par
0,1,2,..,n et la colonne
B par 0,1,4,..,n^2 (cf 1.10.4).
On tape lorsque C1 est en surbrillance :
On obtient dans C1 :
on a en effet :
covariance(A1:A4,B1:B4)=25/4,
stddev(A1:A4)=sqrt(5)/2 et,
stddev(B1:B4)=sqrt(129)/2
et 129*5=645
Dans une ligne d’entrée
On tape :
Ou on tape :
On obtient :
Exercice
Soient X=[1,2], Y=[11,13,14] et N=[[3,4,5],[12,1,2]].
Calculer la covariance et la corrélation de X,Y sachant qu’il y a
N= Nj,k couples Xj,Yk.
Dans une ligne d’entrée
On tape :
On obtient :
On tape :
On obtient :
On a :
simplify(stddev([1,2],[12,15]))=2*sqrt(5)/9
simplify(stddev([11,13,14],[15,5,7]))=16*sqrt(5)/27
et on a bien :
-83/243=-83/160*(sqrt(20)/9)*(16*sqrt(5)/2)
Dans le tableur
On peut disposer les données selon un tableau à double entrée à
condition de rajouter -1 comme dernier argument aux fonctions
covariance et correlation.
On tape :
dans A0 :
"X\ Y" (c’est pour l’esthétique)
dans A1 :
1
dans A2 :
2
dans B0,C0,D0 :
11,13,14
dans B1,C1,D1 :
3,4,5
dans B2,C2,D2 :
12,1,2
Calcul de la covariance ou de la corrélation dans le tableur :
On tape dans E0 :
On obtient dans E0 :
On tape dans E1 :
On obtient dans E1 :
Remarque
On peut bien sûr faire le même calcul dans une ligne d’entrée :
On sélectionne avec la souris A0..2,B,C,D, puis on
tape :
covariance(,-1)
puis, on met le curseur à l’endroit
de l’argument manquant, puis on appuie sur coller,
ou on tape :
On obtient :
On tape :
On obtient :
Attention
Dans une cellule du tableur on ne peut pas désigner
un sous-tableau ou une matrice par :
"référence de la première case de la matrice" :
"référence de sa dernière case de la matrice".
en effet si dans la cellule C0 on tape :
=A0:B4 et on obtient dans la cellule C0 la liste :
[A0,B0,A1,B1,A2,B2] c’est à dire la matrice "aplatie".
Pourtant, si les couples A=a[j] et B=b[j] ont pour
effectif N=n[j] (j=0..p−1),
la covariance (resp la corrélation) de A,B avec effectifs N
peuvent se calculer dans une ligne d’entrée, mais aussi dans le tableur
même si
les données ne figurent pas dans des colonnes consécutives.
Lorsque les colonnes sont consécutives, on peut
reconstituer la matrice en utilisant list2mat, par exemple si on met
les valeurs de A dans la colonne A, les valeurs de B
dans la colonne B et les
effectifs N dans la colonne C on tape dans la cellule
E1 =list2mat(A0:C5,6,3) et on obtient dans la cellule E1 la
matrice cherchée ayant 6 lignes et 3 colonnes A,B,C.
Lorsque les colonnes ne sont pas consécutives par exemple si on met les
effectifs N=n[j] dans la colonne D on
tape alors pour avoir une matrice dans la cellule E1 :
=tran([A0:A5,B0:B5,D0:D5]) et on obtient dans la cellule E1 la
matrice cherchée ayant 6 lignes et 3 colonnes A,B,D.
Pour approcher les données par la droite des moindres carrés qui a pour
équation y=mx+b, on utilise linear_regression.
linear_regression a les mêmes arguments que covariance.
Si linear_regression a comme argument la liste X des xj et la
liste Y des yj, linear_regression renvoie (m, b) tel que
y ≃ m*x+b.
Pour traiter une régression linéaire à 2 ou plusieurs variables on se
reportera à la section 1.11.8.
Avec le tableur
Pour traiter les exemples, on remplit la colonne A par
0,1,2,..,n et la colonne
B par 0,1,4,..,n^2 (cf 1.10.4).
Puis, on tape dans la case C0 :
On obtient dans la case C0 :
Dans une ligne d’entrée
On tape :
Ou on tape
On obtient :
ce qui veut dire que y=5x−5 est la droite qui approche au mieux les points
de coordonnées : (1,1),(2,4),(3,9),(4,16).
Remarques
^2)
Autre exemples
On suppose que l’on a les couples (xj,yj) avec :
x=[0,1,2,3,4,5,6,7,8,9,10] et
y=[7.3,9.53,12.47,16.3,21.24,27.73,36.22,47.31,61.78,80.68,105]
On tape :
On obtient :
c’est donc la fonction linéaire d’équation z=ln(y)=0.267*x+1.99
qui approche au mieux les données.
On suppose qu’il y a nj couples (xj,yj) avec :
x=[1,2,3,4], y=[1,4,9,16], et n=[3,1,5,2]
On tape :
On obtient :
c’est donc la fonction linéaire d’équation y=331*x/70−22/5
qui approche au mieux les données.
On suppose qu’il y a nj,k couples (xj,yk) avec :
x=[1,2], y=[11,13,14], et n=[[3,4,5],[12,1,2]]
On tape :
Ou on tape :
On obtient :
c’est donc la fonction linéaire d’équation y=−83*x/60+143/10 qui approche au mieux les données. On calcule le coefficient de corrélation On tape :
2)On obtient :
Donc R2 ≃ 0.2691015625 ce qui ne justifie pas un ajustement linéaire.
Si R2 est le carré du coefficient de corrélation linéaire de X et de Y si m1 (resp m2) est la pente de la première (resp deuxième) droite de régression linéaire on a :
On sait que le coefficient de correlation est un réel entre -1 et 1 donc
0 ≤ R2 ≤ 1. La valeur de R2 va nous dire si la forme du nuage de
points justifie un ajustement lineaire. Il y a une forte corrélation
linéaire lorsque √1−R2 ≤ 0.5 i.e. lorsque R2 ≥ 0.75.
On a :
Pour dessiner la droite des moindres carrés : la droite qui approche au mieux
les données et qui a pour
équation y=mx+b, on utilise linear_regression_plot.
linear_regression_plot a les mêmes arguments que covariance.
On tape :
On obtient :
c’est donc la fonction linéaire d’équation y=331*x/70−22/5 qui approche au mieux les données.
Supposons que l’on observe 3 variables (X,Y,Z), et que l’on veut savoir
comment Z dépend linéairement de X et de Y.
On a par exemple observé n triplés xj,yj,zj pour j=0..n−1. On
cherche c,a,b pour que le plan z=a*x+b*y+c approche au mieux les
données.
Posons E=∑j=0n−1 (zj−a*xj−b*yj−c)2.
On cherche c,a,b pour que E soit minimum c’est à dire pour que :
∂ E/∂ a=−2*∑j=0n−1 xj*(zj−a*xj−b*yj−c)=0
∂ E/∂ b=−2*∑j=0n−1 yj*(zj−a*xj−b*yj−c)=0
∂ E/∂ c=−2*∑j=0n−1 (zj−a*xj−b*yj−c)=0
On a donc à résoudre un système de 3 équations à 3 inconnues
c,a,b.
Soit U la matrice de n lignes et 3 colonnes ayant comme ligne j :
[1,xj,yj] avec j=0..n−1.
Le système à résoudre est :
[
| n | ∑xj | ∑yj |
| ∑xj | ∑xj2 | ∑xjyj |
| ∑yj | ∑xjyj | ∑yj2 |
] [
| c |
| a |
| b |
] = [
| ∑zj |
| ∑xj zj |
| ∑yj zj |
] =tran(U) [
| z0 |
| .... |
| zn−1 |
]
On remarque que la matrice associée au système précédent s’écrit :
| A=tran(U)*U= | ⎡ ⎢ ⎢ ⎣ |
| ⎤ ⎥ ⎥ ⎦ |
La solution c,a,b du système est donc : inv(A)*tran(U)*Z
Suppopsons que l’on a mis les données, dans le tableur (par exemple n=192)
comme ceci :
- en A une colonne remplit avec des 1,
- en B une colonne remplit avec les xj et représentant
X,
- en C une colonne remplit avec les yj et représentant
Y,
- en D une colonne remplit avec les zj et représentant
Z.
Dans la case de sélection on marque :
A0..A191,B,C
On utilise le menu du tableur
FichblacktrianglerightSauver selection vers variable
et on tape U comme nom de variable. Cela définira la matrice U
égale à la sélection.
Puis, on met dans la case de sélection D0..D191 et on utilise à
nouveau le menu du tableur
FichblacktrianglerightSauver selection vers variable
et on tape Z comme nom de variable. Cela définira le vecteur Z
égale à la sélection.
On définit A en tapant : A:=tran(U)*U
Il ne reste plus qu’à taper dans une ligne de commande :
(c,a,b):=col(inv(A)*tran(U)*Z,0)
pour définir c,a,b.
Remarque
Bien sûr il faut que la matrice A=tran(U)*U soit inversible !!!!
On peut aussi taper :
B:=border(A,op(-tran(Z)*U)) puis
C:=rref(B),
puis résoudre C*[[c],[a],[b]]=0.
Pour approcher les données par une fonction exponnentielle qui a pour
équation y=b*exp(m*x)=b*ax, on utilise exponential_regression.
exponential_regression a les mêmes arguments que covariance.
Si exponential_regression a comme argument la liste X des xj
et la liste Y
des yj, exponential_regression renvoie (a, b) tel que
y ≃ bax.
On tape dans la case C1 :
ou on tape dans une ligne d’entrée :
On obtient :
On tape dans une ligne d’entrée :
On obtient :
c’est donc la fonction expopnentielle d’équation :
y=7.30853268031*(1.30568684451)x qui approche au mieux les données.
Remarque
On a :
exp(0.266729219953,1.989042525894)=(1.30568684451, 7.30853268031)
Pour dessiner la fonction exponnentielle qui a pour
équation y=b*exp(m*x)=b*ax, et qui approche au mieux les données, on
utilise exponential_regression_plot.
exponential_regression_plot a les mêmes arguments que
covariance.
On tape dans l’écran geo :
On obtient :
car c’est la fonction expopnentielle d’équation :
y=7.30853268031*(1.30568684451)x qui approche au mieux les données.
Pour approcher les données par une fonction logarithmique qui a pour
équation y=m lnx+b, on utilise logarithmic_regression.
logarithmic_regression a les mêmes arguments que covariance.
Si logarithmic_regression a comme argument la liste X des xj et
la liste Y des yj, logarithmic_regression renvoie (m, b) tel
que y ≃ m *lnx+b.
On tape dans la case C2 :
ou on tape dans une ligne d’entrée :
ou on tape dans une ligne d’entrée :
On obtient :
c’est donc la fonction logarithme d’équation :
y=10.1506450002ln(x)−0.564824055818
qui approche au mieux les données.
Pour dessiner le graphe de la fonction logarithmique qui a pour
équation y=m lnx+b, et qui approche au mieux les données, on utilise
logarithmic_regression_plot.
logarithmic_regression_plot a les mêmes arguments que
covariance.
On tape dans l’écran geo :
On obtient :
car c’est la fonction logarithme d’équation :
y=10.1506450002ln(x)−0.564824055818
qui approche au mieux les données.
Pour approcher les données par une fonction polynomiale d’équation
y=a0xn+..+an, on utilise polynomial_regression.
polynomial_regression a les mêmes arguments que covariance.
Si polynomial_regression a comme arguments la liste des xj, la liste
des yj et le degré n du polynôme, polynomial_regression
renvoie [an,..., a0]) tel que y ≃ an*xn+....+a0.
On tape dans le tableur :
ou on tape dans une ligne d’entrée :
ou on tape dans une ligne d’entrée :
On obtient :
c’est donc le polynôme d’équation y=x2 qui approche au mieux les données.
Pour approcher les données par une fonction puissance d’équation
y=bxm, on utilise power_regression.
power_regression a les mêmes arguments que covariance.
Si power_regression a comme argument la liste des xj et la liste
des yj, power_regression renvoie (m, b) tel que y ≃ bxm.
On tape dans le tableur :
ou on tape ddans une ligne d’entrée :
ou on tape dans une ligne d’entrée :
On obtient :
c’est donc la fonction puissace d’équation y=1*x2 qui approche au mieux les données.
Pour approcher les données par une fonction puissance d’équation
y=bxm, on utilise power_regression_plot.
power_regression_plot a les mêmes arguments que covariance.
On tape dans l’écran geo :
On obtient :
car c’est la fonction puissace d’équation y=1*x2 qui approche au mieux les données.
Définition
On appelle fonction de répartition d’une variable aléatoire x sur
l’espace probabilisé Ω la fonction F définie pour tout x réel
par :
| F(x)=Prob(X≤ x) |
Propriétés
Définition
On dit qu’une variable aléatoire X est absolument continue si et seulement
si il existe une fonction f, appelée densité de probabilité de X,
telle que :
| F(x)= | ∫ |
| f(t)dt |
Règle
Le nom de la fonction de répartition
d’une loi est le nom de la loi, suivi par _cdf, et pour la fonction de
répartition inverse par _icdf : cdf =cumulated distribution
function = fonction de répartition.
Les premiers paramètres sont les paramètres de la loi et le dernier
paramètre le nom de la variable.
On définit les fonctions suivantes :
normald(t) par exp(−(t2)/2)/√2*pi
normald(µ,σ,t) par 1/σ√2πexp(−1/2((t−µ)/σ)2)
normal_cdf(x)= Proba(X≤ x) avec X∈ N(0,1) : c’est la
fonction de répartition de la loi normale centrée réduite.
normal_icdf(t) =h équivaut à Proba(X≤ h)=t avec
X∈ N(0,1) : c’est l’inverse de la fonction de répartition de la
loi normale centrée réduite.
normal_cdf(µ,σ,x)=Proba(X≤ x) avec X∈ N(µ,σ) :
c’est la fonction de répartition de la loi normale
de moyenne µ et d’écart-type σ.
normal_icdf(µ,σ,t) =h équivaut à Proba(X≤ h)=t avec
X∈ N(µ,σ) : c’est l’inverse de la fonction de
répartition de la loi normale de moyenne µ et d’écart-type σ.
normal_cdf(a,b)=normal_cdf(b)-normal_cdf(a)
normal_cdf(µ,σ,a,b)=normal_cdf(µ,σ,b)-normal_cdf(µ,σ,a)
binomial(n,k,p)=comb(n,k)*p^k*(1-p)^n-k
binomial_cdf(n,p,x)=Proba(X ≤ x) avec X∈ B(n,p) :
c’est la fonction de répartition de la loi binomiale
de paramètre n,p c’est à dire
de moyenne np et d’écart-type √np(1−p).
binomial_icdf(n,p,t)= h équivaut à Proba(X≤ h)=t avec
X∈ B(n,p) : c’est l’inverse de la
fonction de répartition de la loi
binomiale de paramètres n et p c’est à dire
de moyenne np et d’écart-type √np(1−p).
poisson(m,k)= exp(-m)*m^k/k!
poisson_cdf(µ,x)=Proba(X≤ x) avec X∈ P(µ) :
c’est la fonction de répartition de la loi de Poisson de paramètre µ,
c’est à dire de moyenne µ et d’écart-type µ.
poisson_cdf(µ,x1,x2)=poisson_cdf(µ,x2)-poisson_cdf(µ,x1)
poisson_icdf(µ,t)= h équivaut à Proba(X≤ h)=t avec
X∈ P(µ) : c’est l’inverse de la fonction de répartition de
la loi de Poisson de paramètre µ, c’est à dire de moyenne µ et
d’écart-type µ.
student_cdf(n,x)=Proba(X≤ x) avec X∈ T(n) : c’est la
fonction de répartition de la loi de Student
ayant n degrés de liberté.
student_icdf(n,t)=h équivaut à Proba(X≤ h)=t avec
X∈ T(n) : c’est l’inverse de la fonction de répartition de la
loi de Student ayant n degrés de liberté.
chisquare_cdf(n,x)=Proba(X≤ x) avec X∈ χ2(n) :
c’est la fonction de répartition de la loi du χ2
ayant n degrés de liberté.
chisquare_icdf(n,t)=h équivaut à Proba(X≤ h)=t avec
X∈ χ2(n) : c’est l’inverse de la fonction de répartition de
la loi du χ2 ayant n degrés de liberté.
fisher_cdf(n,k,x)=snedecor_cdf(n,k,x)=Proba(X≤ x) lorsque
X∈ F(n,k) : c’est
la fonction de répartition de la loi de Fisher ayant n,k degrés de
liberté.
fisher_icdf(n,k,t)=snedecor_icdf(n,k,t)=h ce qui veut dire que
Proba(X≤ h)=t avec
X∈ F(n,k) : c’est l’inverse de la fonction de répartition de la
loi de Fisher ayant n,k degrés de liberté.
UTPC,UTPF,UTPN,UTPT avec C pour χ2, F pour Fisher,
N pour Normale et S pour Student représentent le complément à
1 de la fonction de répartition correspondante.
Par exemple :
UTPN(x)=1-normal_cdf(x)
Mais attention : UTPN(µ ,σ2,x)=1-normal_cdf(µ ,σ,x)