


Si a et b sont des entiers ou des entiers de Gauss :
iquo(a,b) renvoie le quotient q de la division euclidienne de a par b et
irem(a,b) renvoie le reste r de la division euclidienne de a par b.
q et r vérifient :
si a et b sont entiers a=b*q+r avec 0 ≤ r<b
si a et b sont des entiers de Gauss a=b*q+r avec |r|2) ≤ |b|2/2.
Par exemple si a=−2+6*i et si b=1+3*i on a :
q=2+i et r=−1−i
Si a et b sont des entiers relatifs smod(a,b) renvoie le reste
symétrique rs de la division euclidienne de a par b.
q et rs vérifient :
a=b*q+rs avec −b/2<rs ≤ b/2
Exemples :
smod(7,4)=-1
smod(-10,4)=-2
smod(10,4)=2
Remarque
mod (ou %) est une fonction infixée et désigne un élément
de Z/nZ.
On a : 7 mod 4=-1%4 désigne un élément de Z/4Z mais
smod(7,4)=(7%4)%0=-1 désigne un entier.
| = |
| + |
| + |
|
Démontrer que :
| q>0 |
| < |
| ≤ |
|
| − |
| = |
|
| u=a(q+1) |
Démontrer que :
| v≤ b<a<u |
Si r=0, vérifier que :
| = |
|
Puis, on recommence :
on divise a1 par b1.
On trouve un quotient q1 et un reste r1.Si r1 est nul, vérifier
que :
| = |
| + |
|
Si r1 n’est pas nul, on recommence.
Montrer qu’il existe une suite finie d’entiers Q0, Q1,...Qn strictement croissante telle que :
| = |
| + |
| +...+ |
|
|
On suppose que la fraction NUM/DENOM∈]0;1[.
L’algorithme s’écrit en langage non fonctionnel :
DENOM →A
NUM→B
Quotient(A, B)→Q
Reste(A, B)→R
tantque R ≠0 faire
Q+1→D
Afficher D
B-R→B
A*D→A
Quotient(A, B)→Q
Reste(A, B)→R
ftantque
Afficher Q
On écrit la fonction decomp qui va décomposer selon l’algorithme la
fraction frac. Cette fonction va renvoyer la liste lres égale
à [Q0,..Qn] avec 0<Q0<,..<Qn et
frac=1/Q0+..+1/Qn.
Attention frac=b/a et donc fxnd(frac)=fxnd(b/a)=[b,a].
decomp(frac):={
local a,b,l,q,r,lres;
l:=fxnd(frac);
b:=l[0];
a:=l[1];
q:=iquo(a,b);
r:=irem(a,b);
lres:=[];
while (r!=0) {
lres:= concat(lres, q+1);
b:=b-r;
a:=a*(q+1);
q:=iquo(a,b);
r:=irem(a,b);
}
lres:=concat(lres,q);
return lres;
}
On tape :
decomp(151/221)
On obtient :
[2,6,61,5056,40895962,4181199228867648]
On vérifie :
1/2+1/6+1/61+1/5056+1/40895962+1/4181199228867648
On obtient :
151/221
On peut écrire un programme pour faire le vérification :
size(l) est égal à la longueur de la liste l
verifie(l):={
local s,k,res;
s:=size(l);
res:=0;
for (k:=0;k<s;k++){
res:=res+1/l[k];
}
return res;
}
On tape :
verifie([2,6,61,5056,40895962,4181199228867648])
On obtient :
151/221
Soient A et B deux entiers positifs dont on cherche le PGCD.
L’algorithme d’Euclide est basé sur la définition récursive du PGCD :
|
où A mod B désigne le reste de la division euclidienne de A par B.
Voici la description de cet algorithme :
on effectue des divisions euclidiennes successives :
|
Après un nombre fini d’étapes, il existe un entier n tel que :
Rn = 0.
on a alors :
PGCD(A,B)= PGCD(B,R1) =...
PGCD(Rn−1,Rn) = PGCD(Rn−1,0) = Rn−1
-Version itérative
Si B≠ 0 on calcule R=A modB, puis avec B dans le rôle
de A (en mettant B dans A ) et R dans le rôle de B ( en mettant
R dans B) on recommence jusqu’à ce que B=0, le PGCD est alors égal
à A.
fonction PGCD(A,B) local R
tantque B ≠ 0 faire
A mod B=>R B=>A R=>B ftantque retourne A ffonction
-Version récursive
On écrit simplement la définition récursive vue plus haut.
fonction PGCD(A,B)
Si B ≠ 0 alors
retourne PGCD(B,A mod B) sinon retourne A fsi ffonction
- Version itérative :
pgcd(a,b):={
local r;
while (b!=0){
r:=irem(a,b);
a:=b;
b:=r;
}
return(a);
};
- Version récursive.
pgcdr(a,b):={
if (b==0)
return(a);
else
return(pgcdr(b,irem(a,b)));
};
-Version itérative :
pgcd:=proc(x,y) local a,b,r: a:=x: b:=y: while (b>0) do r:=irem(a,b): a:=b: b:=r: od: RETURN(a): end:
-Version récursive :
pgcd:=proc(a,b) if (b=0) then RETURN(a) else RETURN(pgcd(b,irem(a,b))): fi: end:
-Version itérative :
pgcd:=proc(a,b) local r: begin while (b>0) do r:=a mod b: a:=b: b:=r: end_while: return(a): end_proc;
-Version récursive :
pgcd:=proc(a,b) begin if (b=0) then return(a) else return(pgcd(b,a mod b)): end_if: end_proc;
-Version itérative
:pgcd(a,b) :Func :Local r
:While b ≠ 0
:mod(a,b)=>r :b=>a :r=>b :EndWhile :Return a :EndFunc
-Version récursive
:pgcd(a,b) :Func
:If b ≠ 0 Then
:Return pgcd(b, mod(a,b)) :Else :Return a :EndIf :EndFunc
On rappelle que ℤ[i]={m+n*i, (m,n)∈ ℤ2}.
Soient a ∈ ℤ[i] et b ∈ ℤ[i]−{0}, alors on dit que le quotient q
de a par b est l’affixe du (ou des) point(s), le plus proche pour le
module, du point d’affixe a/b.
On tape :
quotient(a,b):={
local q1,q2,c;
c:=normal(a/b);
q1:=re(c);
q2:=im(c);
return round(q1)+i*round(q2);
}:;
pgcdzi(a,b):={
local q,r;
tantque b!=0 faire
q:=quotient(a,b);
r:=a-b*q;
a:=b;
b:=r;
ftantque;
//on normalise
si re(a)<0 et im(a)<=0 alors retourne -a;fsi;
si im(a)<0 alors retourne i*a;fsi;
si re(a)<=0 alors retourne -i*a;fsi;
retourne a;
}:;
On tape :
pgcdzi(3+i,3-i)
On obtient :
1+i
On tape :
pgcdzi(7+i,-6+17*i)
On obtient :
3+4*i
On rappelle que ℤ[i√2]={m+i*n√2, (m,n)∈ ℤ2}.
Soient a ∈ ℤ[i√2] et b ∈ ℤ[i√2]−{0}, alors on dit que le
quotient q de a par b est l’affixe du (ou des) point(s), le plus proche
pour le module, du point d’affixe a/b.
On tape :
quorest(a,b):={
local q1,q2,q,r,c;
c:=normal(a/b);
q1:=normal(round(re(c)));
q2:=normal(round(im(c)/sqrt(2)));
q:= q1+i*q2*sqrt(2);
r:=simplify(a-b*q);
return q,r;
}:;
pgcdzis2(a,b):={
local r;
tantque b!=0 faire
r:=quorest(a,b)[1];
a:=b;
b:=r;
ftantque;
//on normalise
si re(a)<0 alors retourne -a;fsi;
retourne a;
}:;
On tape :
pgcdzis2(3+i*sqrt(2),3-i*sqrt(2))
On obtient :
1
On tape :
pgcdzis2(4+5*i*sqrt(2),-2+3*i*sqrt(2))
On obtient :
2-(3*i)*sqrt(2)
Dans ce paragraphe la fonction Bezout(A,B) renvoie la liste {U, V, PGCD(A,B)} où U et V vérifient : A × U + B × V = PGCD(A,B)
L’algorithme d’Euclide permet aussi de trouver un couple U et V vérifiant:
A × U + B × V= PGCD(A,B)
En effet, si on note A0 et B0 les valeurs de A et de B du début on a :
|
Puis on fait évoluer A, B, U, V, W, X de façon à ce que ces
deux relations soient toujours vérifiées. Voici comment
A, B, U, V, W, X évoluent :
- on pose :
A=B × Q+R 0 ≤ R < B ( R = A mod B et Q = E(A / B ))
- on écrit alors :
|
Il reste alors à recommencer avec B dans le rôle de A (B=>A W=>U X=>V) et R dans le rôle de B (R=>B S=>W T=>X ) d’où l’algorithme:
fonction Bezout(A,B) local U,V,W,X,S,T,Q,R 1=>U 0=>V 0=>W 1=>X
tantque B ≠ 0 faire
A mod B=>R
E(A/B)=>Q
//R=A-B*Q
U-W*Q=>S
V-X*Q=>T
B=>A W=>U X=>V
R=>B S=>W T=>X
ftantque
retourne {U, V, A}
ffonction
On peut simplifier l’écriture de l’algorithme ci-dessus en utilisant moins de
variables : pour cela on utilise les listes LA, LB, LR pour mémoriser
les triplets {U, V, A}, {W, X, B} et {S, T, R}.
Ceci est très commode car les logiciels de calcul savent ajouter des listes
de même longueur (en ajoutant les éléments de même indice) et savent
aussi multiplier une liste par un nombre (en multipliant chacun des
éléments de la liste par ce nombre).
fonction Bezout(A,B)
local LA LB LR
{1, 0, A}=>LA
{0, 1, B}=>LB
tantque LB[3] ≠ 0 faire
LA-LB*E(LA[3]/LB[3])=>LR LB=>LA LR=>LB ftantque retourne LA ffonction
Si on utilise des variables globales pour A, B, D, U, V, T, on peut voir
la fonction Bezout comme calculant à partir de A B, des valeurs
qu’elle met dans U, V, D (AU+BV=D), grâce à une variable locale
Q.
On écrit donc une fonction sans paramètre : seule la variable Q doit être locale à la foncton alors que les autres variables A, B ...
sont globales.
Bezout fabrique U, V, D vérifiant A*U+B*V=D à partir de A et B.
Avant l’appel récursif (on présérve E(A/B)=Q et on met A et
B à jour ( nouvelles valeurs), après l’appel les variables U, V, D vérifient
A*U+B*V=D (avec A et B les nouvelles valeurs), il suffit
alors de revenir aux premières valeurs de
A et B en écrivant :
B*U+(A-B*Q)*V=A*V+B*(U-V*Q)
On écrit alors :
fonction Bezout local Q Si B != 0 faire E(A/B)=>Q A-B*Q=>R B=>A R=>B Bezout U-V*Q=>W V=>U W=>V sinon 1=>U 0=>V A=>D fsi ffonction
On peut définir récursivement la fonction Bezout par:
Bezout(A,0)={1, 0, A}
Si B ≠ 0 il faut définir Bezout(A,B) en fonction de Bezout(B,R) lorsque R=A−B × Q et Q=E(A/B).
On a:
|
Donc:
|
D’où si B ≠ 0 et si Bezout(B,R)=LT on a :
Bezout(A,B)={LT[2], LT[1]−LT[2] × Q, LT[3]}.
fonction Bezout(A,B) local LT Q R
Si B ≠ 0 faire
E(A/B)=>Q
A-B*Q=>R
Bezout(B,R)=>LT
retourne {LT[2], LT[1]-LT[2]*Q, LT[3]}
sinon retourne {1, 0, A}
fsi
ffonction
- Version itérative avec les listes
bezout(a,b):={
//renvoie [u,v,d] tels que a*u+b*v=pgcd(a,b) (fct iterative)
local la,lb,lr,q,lb2;
la:=[1,0,eval(a)];
lb:=[0,1,eval(b)];
lb2:=eval(b);
while (lb2 !=0){
q:=iquo(la[2],lb2);
lr:=la+(-q)*lb;
la:=lb;
lb:=lr;
lb2:=lb[2];
}
return(la);
};
- Version récursive avec les listes
bezoutr(a,b):={
//renvoie [u,v,d] tels que a*u+b*v=pgcd(a,b) (fct recursive)
local lb,q,r;
if (b!=0) {
q:=iquo(a,b);
r:=irem(a,b);
lb:=bezoutr(b,r);
return([lb[1],lb[0]+(-q)*lb[1],lb[2]]);
} else
return([1,0,a]);
};
Dans cette section, on ne suppose pas connue une table de nombres premiers : on ne se sert donc pas du programme crible.
fonction factprem(N)
local D FACT
2 => D
{} => FACT
tantque N<= 1 faire
si N mod D = 0 alors
concat(FACT,D) => FACT
N/D => N
sinon
D+1 => D
fsi
ftantque
retourne FACT
ffonction
fonction factprem1(N)
local D FACT
2 => D
{} => FACT
tantque D*D!= N faire
si N mod D = 0 alors
concat(FACT,D) => FACT
N/D=> N
sinon
D+1 => D
fsi
ftantque
concat(FACT,N) => FACT
retourne FACT
ffonction
Dans la liste FACT, on a les diviseurs premiers éventuellement
plusieurs fois, par exemple :
factprem1(12)={2,2,3}.
Dans la liste FACT, on fait suivre chaque diviseur premier par son
exposant, par exemple :
factprem2(12)={2,2,3,1}.
fonction facprem2(N)
local K D FACT
{}=>FACT
0 => K
tantque N mod 2 == 0 faire
K+1 => K
N/2 => N
ftantque
si K !=0 alors
concat(FACT,{2 K}) => FACT
fsi
3 =>D
tantque D*D<= N faire
0 => K
tantque N mod D = 0 faire
K+1 => K
N/D => N
ftantque
si K !=0 alors
concat(FACT,{D K})=> FACT
fsi
D+2 => D
ftantque
si N != 1 alors
concat(FACT,{N 1})=> FACT
fsi
retourne FACT
ffonction
fonction factprem3(N)
local J,D,FACT
2=>D
{}=>FACT
tantque (D*D<=N) faire
0=>J
tantque (N mod D=0) faire
N/D=>N
J+1=>J
ftantque
si (J!= 0) alors concat(FACT,{D,J})=>FACT fsi
si (D<4) alors
2*D-1=>D
sinon
D+(4*D mod 6)=>D
fsi
ftantque
si (N !=1) alors concat(FACT,{N,1})=>FACT fsi
retourne(FACT)
ffonction
On traduit la troisième amélioration.
factprem(n):={
//decompose n en facteur premier dans la liste l de dimension s
local j,d,s,l;
d:=2;
s:=0;
l:=[];
while (d*d<=n) {
j:=0;
while (irem(n,d)==0){
n:=iquo(n,d);
j:=j+1;
}
if (j!=0) {
l:=concat(l,[d,j]);
s:=s+2;
}
if (d<4) {
d:=2*d-1;
}
else {
d:=d+irem(4*d,6);
}
}
if (n!=1) {
l:=concat(l,[n,1]);
s:=s+2;
}
return([l,s]);
};
Pour effectuer la décomposition en facteurs premiers de n, on utilise la
table des nombres premiers fabriquée par le crible : on ne teste ainsi que
des nombres premiers.
Si on peut écrire N=A*DJ avec PGCD(A,D)=1 et J>0 alors DJ est un
facteur de la décomposition de N.
On écrit tout d’abord la fonction ddiv(N,D) qui renvoie :
- soit la liste :
[ N,[]] si D n’est pas un diviseur de N,
- soit la liste :
[A,[D,J]] si N=A*DJ avec PGCD(A,D)=1 et J>0.
DJ est alors un diviseur de N et A=N/DJ .
fonction ddiv(N,D)
//ddiv renvoie [a,[d,j]] (n=a*d^j, pgcd(a,d)=1) si j!=0 sinon [n,[]]
local L,J
0=>J
tantque (N mod D)=0) faire
N/D=>N
J+1=>J
ftantque
si (J=0) alors
{N,{}}=>L
sinon
{N,{D,J}}=>L
fsi
retourne(L)
ffonction
On cherche la liste des nombres premiers plus petit que √N et on met cette liste dans la variable PREM. Lorsque N>1, on teste si ces nombres premiers sont des diviseurs de N en utilisant ddiv.
fonction criblefact(N)
//decomposition en facteurs premiers de n
//en utilisant ddiv et crible
local D,PREM,S,LD,LDIV;
PREM:=crible(floor(sqrt(N)));
S:=dim(PREM);
LDIV:={};
1=>K
tantque (K<=S et N>1) faire
ddiv(N,PREM[K])=>LD
concat(LDIV,ld[2])=>LDIV;
LD[1]=>N
K+1=>K
ftantque
si (N != 1) alors
concat(LDIV,[N,1])=>LDIV;
fsi
retourne(LDIV);
}
ddiv(n,d):={
//ddiv renvoie [a,[d,j]] (n=a*d^j, pgcd(a,d)=1) si j!=0
//sinon [n,[]]
local l,j;
j:=0;
while (irem(n,d)==0){
n:=iquo(n,d);
j:=j+1;
}
if (j==0){
l:=[n,[]];
} else {
l:=[n,[d,j]];
}
return(l);
}
criblefact(n):={
//decomposition en facteurs premiers de n
//en utilisant ddiv et crible
local d,prem,s,ld,ldiv;
prem:=crible(floor(sqrt(n)));
s:=size(prem);
ldiv:=[];
for (k:=0;k<s;k++){
ld:=ddiv(n,prem[k]);
ldiv:=concat(ldiv,ld[1]);
n:=ld[0];
k:=k+1;
}
if (n!=1){
ldiv:=concat(ldiv,[n,1]);
}
return(ldiv);
}
L’algorithme naïf :
pour j de 1 a n faire
si (j divise n) alors
afficher j
fsi
fpour
Les élèves remarquent que l’on peut avoir les diviseurs deux par deux.
pour j de 1 a E(√n) faire
si (j divise n) alors
afficher j, n/j
fsi
fpour
Malheureusement, lorsque l’entier n est le carré de p, p figure deux
fois dans l’affichage des diviseurs.
On améliore donc l’algorithme :
1 → j
tantque j<√n faire
si (j divise n) alors
afficher j, n/j
fsi
j+1 → j
ftantque
si j·j=n alors
afficher j
fsi
Remarque
Les programmes sont ensuite mis sur des calculatrices, c’est pourquoi les
algorithmes précédents utilisent la commande afficher. Si on veut
écrire un programme avec Xcas on fera une fonction : on mettera les
diviseurs dans une liste qui sera à la fin la valeur de la fonction en
utilisant la commande retourne par exemple :
nbdivis(n):={
local j, L,sn;
L:=[];
j:=1;
sn:=sqrt(n)
tantque j<sn faire
si irem(n,j)==0 alors L:=concat(L,[j,n/j]); fsi;
j:=j+1;
ftantque;
si j*j==n alors L:=append(L,j) fsi;
retourne L;
}:;
On décompose n en facteurs premiers, puis on donne aux exposants de ces facteurs premiers toutes les valeurs possibles. Si n=abcγ l’exposant de a paut prendre α+1 valeurs (0..α), celui de b peut prendre β+1 valeurs et celui de c peut prendre γ+1 valeurs donc le nombre de diviseurs de n est (α+1)*(β+1)*(γ+1).
Déscription de l’algorithme sur un exemple :
n=360=23*32*5
n a donc (3+1)*(2+1)*(1+1)=24 diviseurs.
On les écrit en faisant varier le triplet représentant les exposants avec
l’ordre :
(0,0,0),(1,0,0),(2,0,0),(3,0,0),
(0,1,0),(1,1,0),(2,1,0),(3,1,0),
(0,2,0),(1,2,0),...,
(0,2,1),(1,2,1),(2,2,1),(3,2,1))
On a (a1,β,γ) < (b1,b2,b3) si :
γ<b3 ou
γ=b3 et β<b2 ou
γ=b3 et β=b2 et a1<b1.
On obtient les 4*3*2=24 diviseurs de 360 :
1,2,4,8,3,6,12,24,9,18,36,72,5,10,20,40,15,30,60,120,45,90,180,360.
que l’on peut écrire en le tableau suivant :
1,2,4,8 (les puissances de 2)
3,6,12,24 (3*les puissances de 2)
9,18,36,72 (3*3*les puissances de 2)
5,10,20,40 (5*les puissances de 2)
15,30,60,120 (5*3*les puissances de 2)
45,90,180,360 (5*3*3*les puissances de 2).
Comment obtient-on la liste des diviseurs de abcγ
à partir de la liste L1 des diviseurs de abβ ?
Il suffit de rajouter à L1 la liste L2 constituée par :
c*L1,...,cL1
Dans le programme cette liste de diviseurs (L1) sera donc constituée
au fur et à mesure au moyen d’une liste (L2) qui correspond au parcours
de l’arbre.
On initialise L1 avec {1}, puis on rajoute à L1
la liste L2 formée par :
a*L1,...,aL1.
Puis on recommence avec le diviseur suivant :
on rajoute à L1
la liste L2 formée par b*L1,...,bL1 etc...
La liste L1 est la liste destinée à contenir les diviseurs de N.
Au dèbut L1={1} et L2={}.
Pour avoir la liste des diviseurs de N, on cherche A le premier
diviseur de N et on cherche a la puissance avec quelle A
divise N.
On définit la liste L2 :
L2 est obtenue en concaténant, les listes L1*A, L1*A2,
...,L1*Aa : au début L1={1} donc
L2={A,A2,...,Aa}.
On modifie la liste L1 en lui concaténant la liste L2, ainsi
L1={1,A,A2,...,Aa}.
Puis, on vide la liste L2. On cherche B le deuxième diviseur
éventuel de N et on
cherche b la puissance avec quelle B divise N.
On définit la nouvelle liste L2 :
L2 est obtenue en concaténant, les listes L1*B, L1*B2,
..., L1*Bb (c’est à dire
L2={B,B*A,B*A2,..,B*AaB2,B2*A,B2*A2,..,B2*Aa,..,Bb*Aa,})
On modifie la liste L1 en lui concaténant la liste L2, ainsi :
L1={1,A,A2,...,Aa,B,B*A,B*A2,...,B*Aa,...,Bb,Bb*A,Bb*A2,...,Bb*Aa}.
Et ainsi de suite, jusqu’à avoir epuisé tous les diviseurs de N.
fonction NDIV0(N)
local D,L1,L2,K
2 => D
{1} => L1
tant que (N ≠ 1) faire
{}=>L2
0=> K:
tantque ((N MOD D) =0) faire
N/D=> N
K+1 =>K
concat(L2,L1*D K)=> L2
ftantque
concat(L1,L2)=> L1
D+1=> D
ftantque
retourne(L1)
ndiv0(n):={
local d,l1,l2,k;
d:=2;
l1:=[1];
while (n!=1) {
l2:=[];
k:=0;
while (irem(n,d)==0) {
n:=iquo(n,d);
k:=k+1;
l2:=concat(l2,l1*d^k);
}
l1:=concat(l1,l2);
d:=d+1;
}
return(l1);
}
On peut améliorer ce programme en calculant l1*d^k au fur et
à mesure sans utiliser k....
On a en effet sur l’exemple précédent n=360=23*32*5 :
l1:=[1];
les puissances de 2 sont obtenus avec
l2:=l1 on a alors l2:=[1]
l2:=l2*2;l1:=concat(l1,l2) on a alors l2:=[2];l1:=[1,2]
l2:=l2*2;l1:=concat(l1,l2) on a alors l2:=[4];l1:=[1,2,4]
l2:=l2*2;l1:=concat(l1,l2) on a alors l2:=[8];l1:=[1,2,4,8]
les puissances de 3 sont obtenus avec
l2:=l1 on a alors l2:=[1,2,4,8]
l2:=l2*3;l1:=concat(l1,l2) on a alors l2:=[3,6,12,24]; l1:=[1,2,4,8,3,6,12,24]
l2:=l2*3;l1:=concat(l1,l2) on a alors l2:=[9,18,36,72]; l1:=[1,2,4,8,3,6,12,24,9,18,36,72]
les puissances de 5 sont obtenus avec
l2:=l1 on a alors l2:=[1,2,4,8,3,6,12,24,9,18,36,72]
l2:=l2*5;l1:=concat(l1,l2) on a alors l2:=[5,10,20,40,15,30,60,120,45,90,180,360]
donc
l1:=[1,2,4,8,3,6,12,24,9,18,36,72,5,10,20,40,15,30,60,120,45,90,180,360]
On tape :
ndiv1(n):={
local d,l1,l2;
d:=2;
l1:=[1];
while (n!=1) {
l2:=l1;
while (irem(n,d)==0) {
n:=iquo(n,d);
l2:=l2*d
l1:=concat(l1,l2);
}
d:=d+1;
}
return(l1);
}:;
On peut encore améliorer ce programme si on tient compte du fait qu’après
avoir éventuellement divisé N par 2 autant de fois qu’on le pouvait,
les diviseurs potentiels de N sont impairs.
On remplace alors :
D+1 => D
par :
si D=2 alors
D+1 => D
sinon
D+2 => D
fsi
On améliore le programme précédent en remarquant que,
si le diviseur potentiel D est tel que D>√N, c’est que
N est premier ou vaut 1.
On ne continue donc pas la recherche des diviseurs de N et quand
N est diffèrent de 1 on complète
L1 par L1*N.
Et aussi, on ne teste comme diviseur potentiel de N, que les
nombres 2, 3, puis les nombres de la forme 6*k−1 ou de la forme 6*k+1
(pour k∈ ℕ).
On remplace donc :
si D=2 alors
D+1 => D
sinon
D+2 => D
fsi
par :
si D<4 alors
2*D-1 => D
sinon
D+(4*D mod6) => D
fsi
fonction ndiv2(N)
local D,L1,L2,K
2 => D
{1} => L1
tant que (D ≤ √N) faire
{}=>L2
0=> K:
tantque ((N MOD D) =0) faire
N/D=> N
K+1 =>K
concat(L2,L1*D K)=> L2
ftantque
concat(L1,L2)=> L1
si D<4 alors
2*D-1 => D
sinon
D+(4*D mod6) => D
fsi
ftantque
si N ≠ 1 alors
concat(L1,L1*N) =>L1
fsi
retourne(L1)
ndivi(n):={
local d,l1,l2,k;
d:=2;
l1:=[1];
l2:=l1
while (irem(n,d)==0) {
n:=iquo(n,d);
l2:=l2*d
l1:=concat(l1,l2);
}
d:=3;
while (d<=sqrt(n) and n>1) {
l2:=l1;
while (irem(n,d)==0) {
n:=iquo(n,d);
l2:=l2*d
l1:=concat(l1,l2);
}
d:=d+2;
};
if (n!=1) {l1:=concat(l1,l1*n)};
return(l1);
}:;
Si on ne teste pas d<sqrt(n) le programme est plus simple :
ndivis(n):={
local d,l1,l2,k;
d:=2;
l1:=[1];
l2:=l1
while (irem(n,d)==0) {
n:=iquo(n,d);
l2:=l2*d
l1:=concat(l1,l2);
}
d:=3;
while (n>1) {
l2:=l1;
while (irem(n,d)==0) {
n:=iquo(n,d);
l2:=l2*d
l1:=concat(l1,l2);
}
d:=d+2;
};
return(l1);
}:;
Ou bien on utilise ifactors : on obtient un programme plus rapide surtout
lorsqu’il y a de grands facteurs premiers car la
décomposition en facteurs premiers est optimisée.
ndivfact(n) renvoie la liste des diviseurs de n et la longueur de
cette liste.
On calcule la longueur de cette liste en faisant le produit des exposants
augmentés de 1. Par exemple si n=360=23*32*5, la liste des diviseurs
de n=360 a comme longueur sd:=(3+1)*(2+1)*(1+1)=24
La liste l1 va contenir la liste des diviseurs et pour
chaque nouveau diviseur de n, la liste l2 contient les nouveaux
diviseurs qui doivent être rajoutés à l1.
Par exemple si n=360
au début
l1:=[1] et l2:=l1
d:=2 est un diviseur donc
l2:=2*l2 i.e. l2:=[2] et l1:=concat(l1,l2) i.e. l1=[1,2]
d:=2 est encore un diviseur donc
l2:=2*l2 i.e. l2:=[4] et l1:=concat(l1,l2) i.e. l1=[1,2,4]
d:=2 est encore un diviseur donc
l2:=2*l2 i.e. l2:=[8] et l1:=concat(l1,l2) i.e. l1=[1,2,4,8]
On a épuiser le diviseur 2. On recopie l1 dans l2
l2:=l1 i.e. l2=[1,2,4,8]
le nouveau diviseur est 3 donc
l2:=3*l2 i.e. l2:=[3,6,12,24] et l1:=concat(l1,l2) i.e.
l1=[1,2,4,3,6,12,24]
d:=3 est encore un diviseur donc
l2:=3*l2 i.e. l2:=[9,18,36,72] et l1:=concat(l1,l2) i.e.
l1=[1,2,4,8,3,6,12,24,9,18,36,72]
On a épuiser le diviseur 3. On recopie l1 dans l2
l2:=l1 i.e. l2=[1,2,4,8,3,6,12,24,9,18,36,72]
le nouveau diviseur est 5 donc
l2:=5*l2 i.e. l2:=[5,10,20,40,15,30,60,120,45,90,180,360] et
l1:=concat(l1,l2) i.e.
l1=[1,2,4,8,3,6,12,24,9,18,36,72,5,10,20,40,15,30,60,120,45,90,180,360]
On a épuiser tous les diviseurs donc les diviseurs de 360 sont
l1=[1,2,4,8,3,6,12,24,9,18,36,72,5,10,20,40,15,30,60,120,45,90,180,360]
On tape :
ndivfact(n):={
local F,d,l1,l2,k,kd,sf,sd,j;
si n==0 alors retourne "erreur"; fsi;
si n<0 alors n:=-n; fsi;
F:=ifactors(n);
sf:=size(F)-1;
sd:=1;
pour k de 1 jusque sf pas 2 faire
sd:=sd*(F[k]+1);
fpour;
k:=1;
l1:=[1];
while (k<=sf) {
l2:=l1;kd:=F[k];
d:=F[k-1];
pour j de 1 jusque kd faire
l2:=l2*d
l1:=concat(l1,l2);
fpour;
k:=k+2;
};
return l1,sd;
}:;
Comparons les temps d’exécution sur 2 exemples.
On tape :
ndivis(30!);
On obtient :
Temps mis pour l’évaluation: 7.53
On tape :
ndivi(30!);
On obtient :
Temps mis pour l’évaluation: 8.03
On tape :
ndivfact(30!);
On obtient :
Temps mis pour l’évaluation: 7.33
Mais si on tape :
ndivis(30!*907);
On obtient :
Temps mis pour l’évaluation: 19.28
On tape :
ndivi(30!*907);
On obtient :
Temps mis pour l’évaluation: 17.07
On tape :
ndivfact(30!*907);
On obtient :
Temps mis pour l’évaluation: 17.07
Donc dans le 1ier cas ndivis va plus vite et dans le 2nd cas c’est
ndivi qui va plus vite.
On utilise le programme factprem (qui donne la liste des facteurs premiers de N (cf 8.4.2) pour obtenir la liste des diviseurs de N selon l’algorithme utilisé dans NDIV1.
fonction fpdiv(N)
//renvoie la liste des diviseurs de n en utilisant factprem
local L1,L2,L3,D,ex,S
factprem(N)=>L3
dim(L3)=>S
{1}=>L1
pour K de 1 a S-1 pas 2 faire
{}=>L2
L3[K]=>D
L3[K+1]=>ex
pour J de 1 a ex faire
concat(L2,L1*(D^J))=>L2
}
concat(L1,L2)=>L1
}
retourne(L1)
}
fpdiv(n):={
//renvoie la liste des diviseurs de n en utilisant factprem
local l1,l2,l3,d,ex,s;
l3:=factprem(n);
s:=size(l3);
l1:=[1];
for (k:=0;k<s-1;k:=k+2) {
l2:=[];
d:=l3[k];
ex:=l3[k+1];
for (j:=1;j<=ex;j++) {
l2:=concat(l2,l1*(d^j));
}
l1:=concat(l1,l2);
}
return(l1);
}
Pour obtenir la liste des diviseurs de N selon l’algorithme utilisé
dans NDIV1, on utilise le programme criblefact
(cf 8.5.2) qui donne la liste des facteurs premiers de N.
fonction criblediv(N)
//renvoie la liste des diviseurs de n en utilisant factprem
local L1,L2,L3,D,ex,S
criblefact(N)=>L3
dim(L3)=>S
{1}=>L1
pour K de 1 a S-1 pas 2 faire
{}=>L2
L3[K]=>D
L3[K+1]=>ex
pour J de 1 a ex faire
concat(L2,L1*(D^J))=>L2
}
concat(L1,L2)=>L1
}
retourne(L1)
}
criblediv(n):={
//renvoie la liste des diviseurs de n en utilisant criblefact
local l1,l2,l3,d,ex;
l3:=criblefact(n);
s:=size(l3);
l1:=[1];
for (k:=0;k<s-1;k:=k+2) {
l2:=[];
d:=l3[k];
ex:=l3[k+1];
for (j:=1;j<=ex;j++) {
l2:=concat(l2,l1*(d^j));
}
l1:=concat(l1,l2);
}
return(l1);
}
-Premier algorithme
On utilise deux variables locales PUIS et I.
On fait un programme itératif de façon qu’à chaque étape, PUIS
représente AI modN
fonction puimod1 (A, P, N) local PUIS, I 1=>PUIS pour I de 1 a P faire A*PUIS mod N =>PUIS fpour retourne PUIS ffonction
-Deuxième algorithme
On n’utilise ici qu’une seule variable locale PUI, mais on fait varier P de
façon qu’à chaque étape de l’itération on ait :
PUI * AP modN=constante. Au début PUI=1 donc
constante=AP modN (pour la valeur initiale du paramètre P, c’est
à dire que cette constante est égale à ce que doit retourner la
fonction), et, à chaque étape, on utilise l’égalité
PUI*AP modN=(PUI*AmodN)*AP−1 modN, pour diminuer la valeur de P,
et pour arriver à la fin à P=0, et alors on a la constante=PUI.
fonction puimod2 (A, P, N) local PUI 1=>PUI tantque P>0 faire A*PUI mod N =>PUI P-1=>P ftantque retourne PUI ffonction
-Troisième algorithme
On peut aisément modifier ce programme en remarquant que :
A2*P = (A*A)P .
Donc quand P est pair, on a la relation :
PUI*AP = PUI*(A*AmodN)P/2 modN
et quand P est impair, on a la relation :
PUI*AP = (PUI*AmodN)*AP−1modN.
On obtient alors, un algorithme rapide du calcul de AP modN .
fonction puimod3 (A, P, N)
local PUI
1=>PUI
tantque P>0 faire
si P mod 2 =0 alors
P/2=>P
A*A mod N=>A
sinon
A*PUI mod N =>PUI
P-1=>P
fsi
ftantque
retourne PUI
ffonction
On peut remarquer que si P est impair, P−1 est pair.
On peut donc écrire :
fonction puimod4 (A, P, N)
local PUI
1=>PUI
tantque P>0 faire
si P mod 2 =1 alors
A*PUI mod N =>PUI
P-1=>P
fsi
P/2=>P
A*A mod N=>A
ftantque
retourne PUI
ffonction
-Programme récursif
On peut définir la puissance par les relations de récurrence :
A0=1
AP+1 modN =(AP modN )*A modN
fonction puimod5(A, P, N) si P>0 alors retourne puimod5(A, P-1, N)*A mod N sinon retourne 1 fsi ffonction
-Programme récursif rapide
fonction puimod6(A, P, N)
si P>0 alors
si P mod 2 =0 alors
retourne puimod6((A*A mod N), P/2, N)
sinon
retourne puimod6(A, P-1, N)*A mod N
fsi
sinon
retourne 1
fsi
ffonction
puimod(a,p,n):={
//calcule recursivement la puissance rapide a^p modulo n
if (p==0){
return(1);
}
if (irem(p,2)==0){
return(puimod(irem(a*a,n),iquo(p,2),n));
}
return(irem(a*puimod(a,p-1,n),n));
}
Étant donné deux entiers a∈ ℕ* et n∈ ℕ, n≥ 2, on veut
connaitre les différentes valeurs de ap modn pour p ∈ ℕ, c’est
à dire l’orbite de a dans (ℤ/nℤ,×).
On démontre que l’orbite se termine toujours par un cycle puisque ℤ/nℤ
a un nombre fini d’éléments.
| ah=ah+T modn |
Solution
On tape :
(irem(2^p ,24)$(p=0..10))
On obtient : 1,2,4,8,16,8,16,8,16,8,16
donc h=3 et T=2
On utilise la commande member qui teste si un élément est dans une
liste et member renvoie soit l’indice +1, soit 0.
On peut utiliser soit un tantque soit un repeter (tantque non arrêt faire....tantque ou repeter ...jusqua arrêt) et on remarquera
le test d’arrêt. On sait qu’une affectation renvoie la valeur affectée,
donc k:=member(b,L) renvoie soit 0 soit un nombre non nul. On fait une
boucle et on s’arrete quand k:=member(b,L) est non nul.
orbite1(a,n):={
local k,h,T,p,b,L;
L:=[1];
p:=1;
b:=irem(a,n);
tantque !(k:=member(b,L)) faire
L:=append(L,b);
b:=irem(b*a,n);
p:=p+1;
ftantque;
h:=k-1;
T:=p-h;
return h,T,L;
}:;
orbite2(a,n):={
local k,h,T,p,b,L;
L:=[];
p:=0;
b:=1;
repeter
L:=append(L,b);
b:=irem(b*a,n);
p:=p+1;
jusqua (k:=member(b,L));
h:=k-1;
T:=p-h;
return h,T,L;
}:;
On dessine les points du cycle et de 2 périodes avec la couleur a ou la couleur 0 lorsque a=7 :
dessin(a,n):={
local k,h,T,L,P,s,LT;
P:=NULL;
h,T,L:=orbite1(a,n);
s:=dim(L);
LT:=mid(L,h);
L:=concat(concat(L,LT),LT);
pour k de 0 jusque s+2*T-1 faire
P:=P,point(k,L[k]);
fpour;
si a==7 alors return affichage(P,epaisseur_point_3);fsi;
return affichage(P,a+epaisseur_point_3);
}:;
On tape : dessin(2,11)
On tape : dessin(3,11)
On tape : dessin(2,9)
On tape : dessin(3,9)
et on observe.....
On peut rappeler
| an−1=1 modn |
| aφ(n)=1 modn |
On tape :
est_premier_avec(n):={
local L,a;
L:=NULL;
pour a de 1 jusque n-1 faire
si gcd(a,n)==1 alors L:=L,a; fsi;
fpour;
return L;
}:;
Puis, on tape : E:=est_premier_avec(9)
On obtient : 1,2,4,5,7,8
et on a bien : euler(9)=6=dim(E)
Une démonstration rapide de ces théorèmes :
Si a et n sont premiers entre eux, a est inversible dans ℤ/nℤ,×
Soit E l’ensemble des nombres de [1..n] qui sont premiers avec n
(E:=est_premier_avec(n)) et soit Ea l’ensemble des k*a pour
k∈ E. Tous les éléments de Ea sont distincts et inversibles dans
ℤ/nℤ,×: donc
les ensembles E et Ea sont les mêmes. En faisant le produit de tous ces
éléments on obtient Πk∈ Ek=Πk∈ Eak=aφ(n)Πk∈ Ek,
Πk∈ Ek étant inversible dans ℤ/nℤ,×
on en déduit que aφ(n)=1.
- Premier algorithme
On va écrire un fonction booléenne de paramètre N, qui sera égale à
VRAI quand N est premier, et, à FAUX sinon.
Pour cela, on cherche si N posséde un diviseur différent de 1 et
inférieur ou égal à
E(√N) (partie entière de racine de N).
On traite le cas N=1 à part !
On utilise une variable booléenne PREM qui est au départ à VRAI, et
qui passe à FAUX dès que l’on rencontre un diviseur de N.
Fonction estpremier(N) local PREM, I, J
E(√N) =>J
Si N = 1 alors FAUX=>PREM sinon VRAI=>PREM fsi 2=>I
tantque PREM et I ≤J faire
si N mod I = 0 alors
FAUX=>PREM
sinon
I+1=>I
fsi
ftantque
retourne PREM
ffonction
-Première amélioration
On peut remarquer que l’on peut tester si N est pair, et ensuite,
tester si N posséde un diviseur impair.
Fonction estpremier(N) local PREM, I, J
E(√N) =>J
Si (N = 1) ou (N mod 2 = 0) et N≠2 alors
FAUX=>PREM sinon VRAI=>PREM fsi 3=>I
tantque PREM et I ≤J faire
si N mod I = 0 alors
FAUX=>PREM
sinon
I+2=>I
fsi
ftantque
retourne PREM
ffonction
- Deuxième amélioration
On regarde si N est divisible par 2 ou par 3, sinon on regarde si N posséde un diviseur de la forme 6 × k−1 ou 6 × k+1
(pour k∈ ℕ).
Fonction estpremier(N) local PREM, I, J
E(√N) =>J
Si (N = 1) ou (N mod 2 = 0) ou ( N mod 3 = 0) alors FAUX=>PREM sinon VRAI=>PREM fsi si N=2 ou N=3 alors VRAI=>PREM fsi 5=>I
tantque PREM et I ≤J faire
si (N mod I = 0) ou (N mod I+2 =0) alors
FAUX=>PREM
sinon
I+6=>I
fsi
ftantque
retourne PREM
ffonction
estprem(n):={
//teste si n est premier
local prem,j,k;
if ((irem(n,2)==0) or (irem(n,3)===0) or (n==1)) {
return(false);
}
if ((n==2) or (n==3)) {
return(true);
}
prem:=true;
k:=5;
while ((k*k<=n) and prem) {
if (irem(n,k)==0 or irem(n,k+2)==0) {
prem:=false;
}
else {
k:=k+6;
}
}
return(prem);
}
fonction estpremc(N)
//utilise la fonction crible pour tester si n est premier
local PREM,S;
crible(floor(sqrt(N)))=>PREM
dim(PREM)=>S
si (N=1) retourne(FAUX)
pour K de 1 a S faire
si (N mod ,PREM[K])=0)
retourne(FAUX);
fsi
fpour
retourne(VRAI)
ffonction
estpremc(n):={
//utilise la fonction crible pour tester si n est premier
local prem,s;
prem:=crible(floor(sqrt(n)));
s:=size(prem);
if (n==1) return(false);
for (k:=0;k<s;k++){
if (irem(n,prem[k])==0){
return(false);
}
}
return(true);
}
Si N est premier alors tous les nombres K strictement inférieurs à N
sont premiers avec N, donc d’après le petit théorème de Fermat on a :
KN−1 = 1 modN
Par contre, si N n’est pas premier, les entiers K (1<K<N) vérifiant :
KN−1 = 1 modN sont peu nombreux.
La méthode probabiliste de Rabin consiste à prendre au hasard un
nombre K dans l’intervalle [2 ; N−1] (
1< K < N ) et à calculer :
KN−1 mod N
Si KN−1 = 1 mod N on refait un autre tirage du nombre K, et, si
KN−1 ≠ 1 mod N on est sûr que N n’est pas premier.
Si on obtient KN−1 = 1 mod N pour 20 tirages successifs de K on
peut conclure que N est premier avec une probabilité d’erreur faible :
on dit alors que N est pseudo-premier.
Bien sûr cette méthode est employée pour savoir si de grands nombres
sont pseudo-premiers mais on préfére utiliser la méthode de Miller-Rabin
(cf 8.12)
qui est aussi une méthode probabiliste mais qui donne N premier avec une
probabilité d’erreur plus faible (inférieure à (0.25)20 si on a
effectué 20 tirages, soit, une erreur de l’ordre de 10−12).
On suppose que :
hasard(N) donne un nombre entier au hasard entre 0 et N−1.
Le calcul de
KN−1 mod N
se fait grâce à l’algorithme de la puissance rapide (cf page ??).
On suppose que :
powmod(K, P, N) calcule KP modN
Fonction estprem(N) local K, I, P 1=>I 1=>P tantque P = 1 et I < 20 faire hasard(N-2)+2=>K powmod(K, N-1, N)=>P I+1=>I ftantque Si P =1 alors retourne VRAI sinon retourne FAUX fsi ffonction
La fonction powmod existe dans Xcas : il est donc inutile de la programmer.
rabin(n):={
//teste par la methode de Rabin si n est pseudo-premier
local k,j,p;
j:=1;
p:=1;
while ((p==1) and (j<20)) {
k:=2+rand(n-2);
p:=powmod(k,n-1,n);
j:=j+1;
}
if (p==1) {
return(true);
}
return(false);
}
Rappel Le théorème de Fermat :
Si n est premier et si k est un entier quelconque alors kn=k modn.
et donc
Si n est premier et si k est premier avec n alors kn−1=1 modn.
Soit N=561=3*11*17. Il se trouve que l’on a :
pour tout A (A<N), on a AN=A mod N, donc si A est premier avec
N on a AN−1=1 mod N, le test de Rabin est donc en defaut,
seulement pour A non premier avec N.
Par exemple on a :
3560=375 mod 561
11560=154 mod 561
17560=34 mod 561
471560=375 mod 561
mais pour tous les nombres A non multiples de 3, 11 ou 17 on a :
AN−1=1 mod 561.
Par exemple on a :
5560=1 mod 561.
52N−1=1 mod 561.
On risque donc de dire avec le test de Rabbin que 561 est pseudo-premier.
Il faut donc affiner le test en remarquant que si N est premier l’équation:
X2=1 modN n’a pour solution que X=1 modN ou X=−1 modN.
Le test de Miller-Rabin est basé sur cette remarque.
Pour N=561, N−1=560, on a :
560=35*216
1335=208 mod 561
1335*2=67 mod 561
1335*4=1 mod 561
1335*8=1 mod 561...
On vient de trouver que 67 est solution de X2=1 mod561 donc on peut
affirmer que 561 n’est pas premier.
A=13 vérifie le test de Rabin car 13560=1 mod 561
mais ne vérifie pas le test de Miller-Rabin car
1335*2≠ −1 mod561 et 1335*2 ≠ 1 mod561
et pourtant 1335*4=1335*4=1 mod 561
Par contre ce test ne suffit pas pour affirmer qu’un nombre est premier car :
10135=560=−1 mod561 et donc 10135*2=1 mod561 et cela ne
fournit pas de solutions autre que 1 ou -1 à l’équation X2=1 mod561.
L’algorithme est basé sur :
1/ Le petit théorème de Fermat:
AN−1 = 1 modN si N est premier et si A<N.
2/ Si N est premier, l’équation X*X = 1 modN n’a pas d’autres
solutions que X=1 modN ou X=−1 modN.
En effet il existe un
entier k vérifiant X*X−1=(X+1)*(X−1)=k*N donc,
puisque N est premier, N divise X+1 ou X−1. On a donc soit
X=1 modN ou X=−1 modN.
On élimine les nombres pairs que l’on sait ne pas être premiers.
On suppose donc que N est impair et donc que N−1 est pair et s’écrit :
N−1=2t*Q avec t>0 et Q impair.
Si AN−1=1 modN c’est que AN−1 modN est le carré de
B=AN−1/2=A2t−1Q modN.
Si on trouve B≠ 1 modN et B≠ −1 modN on est sûr que N
n’est pas premier.
Si B=−1 modN on recommence avec une autre valeur de A.
Si B=1 modN on peut recommencer le même raisonnement si
N−1/2 est encore pair
(B=AN−1/2=(AN−1/4)2 modN) ou
si N−1/2 est impair, on recommence avec une autre valeur de A.
On en déduit que :
si N−1=2t.Q et
si AN−1 = 1 modN et
si AQ ≠ 1 modN et
si pour 0 ≤ ex < t on a A2ex.Q ≠ −1 modN c’est que N n’est pas premier.
D’où la définition :
Soit N un entier positif impair égal à 1+2t*Q avec Q impair.
On dit que N est pseudo-premier fort de base A si :
soit AQ=1 modN
soit si il existe e, 0 ≤ e<t tel que AQ*2e=−1 modN.
On voit facilement qu’un nombre premier impair est pseudo-premier fort dans
n’importe quelle base A non divisible par N.
Réciproquement on peut montrer que si N>4 n’est pas premier, il existe
au plus N/4 bases A (1<A<N) pour lesquelles N est pseudo-premier fort
de base A.
L’algorithme va choisir au hasard au plus 20 nombres Ak compris entre 2
et N−1 : si N est pseudo-premier fort de base Ak pour k=1..20 alors
N est premier avec une tres forte probabilité égale à
(1/4)20(<10−12).
Bien sûr cette méthode est employée pour savoir si de grands nombres
sont pseudo-premiers.
On suppose que :
hasard(N) donne un nombre entier au hasard entre 0 et N−1.
Le calcul de
KN−1 modN
se fait grâce à l’algorithme de la puissance rapide (cf page ??).
On notera :
powmod(K, P, N) la fonction qui calcule KP mod N
Fonction Miller(N) local Q,P,t,C,A,B,ex si (N=2) alors retourne FAUX si (N mod 2)==0) alors retourne FAUX N-1=>Q 0=>t tantque (Q mod 2 =0) faire t+1=>t E(Q/2)=>Q ftantque //N-1=2^t*Q 20=>C VRAI=>P tantque (C>0 et P) faire hasard(N-2)+2=>A 0=>ex powmod(A, Q, N)=>B si B<>1 alors tant que (B<>1) et (B<>N-1) et (ex<t-1) faire ex+1=>ex powmod(B,2,n)=>B ftantque si (B<>N-1) alors FAUX=>P fsi C-1=>C ftantque retourne P ffonction
La fonction powmod existe dans Xcas : il est donc inutile de la programmer.
miller(n):={
local p,q,t,c,a,b,ex;
if (n==2){return(true);}
if (irem(n,2)==0) {return(false);}
q:=n-1;
t:=0;
while (irem(q,2)==0) {
t:=t+1;
q:=iquo(q,2);
}
//ainsi n-1=q*2^t
c:=20;
p:=true;
while ((c>0) and p) {
//rand(k) renvoie un nombre entier de [0,k-1] si k<999999999
if (n<=10^9) {a:=2+rand(n-2);} else {a:=2+rand(999999999);}
ex:=0;
b:=powmod(a,q,n);
//si b!=1 on regarde si b^{2^(ex)}=-1 mod n (ex=0..t-1)
if (b!=1) {
while ((b!=1) and (b!=n-1) and (ex<=t-2)) {
b:=powmod(b,2,n);
ex:=ex+1;}
//si b!=n-1 c'est que n n'est pas premier
if (b!=n-1) {p:=false;}
}
c:=c-1;
}
return(p);
};
On a besoin ici des fonctions de Xcas :
- asc qui convertit un caractère
ou une chaîne de caractères,
en une liste de nombres et,
- char qui convertit un nombre ou
une liste de nombres en un caractère
ou une chaîne de caractères.
On a :
char(n) pour n entier, (0 ≤ n ≤ 255) donne le caractère
ayant comme code ASCII l’entier n.
char(l) pour une liste d’entiers l (0 ≤ l[j] ≤ 255), donne la
chaîne de caractères dont
les caractères ont pour code ASCII les entiers l[j] qui composent
la liste l.
asc(mot) renvoie la liste des codes ASCII des lettres composant le mot.
Exemples
asc("A")=[65]
char(65)="A"
asc("Bonjour")= [66,111,110,106,111,117,114]
char([66,111,110,106,111,117,114])="Bonjour"
Remarque :
Il existe aussi la fonction ord qui a pour argument une chaîne de
caractères mais qui renvoie le code ASCII de la première lettre de la
chaîne de caractères :
ord("B")= 66
ord("Bonjour")= 66
- Version itérative
Si n<b, il n’y a rien à faire : l’écriture en base b est la même que
l’écriture en base dix et est n.
On divise n par b : n=b*q+r avec 0≤ r<b).
Le reste r de la division euclidienne de n par b
(r:=irem(n,b)) donne le dernier chiffre de l’écriture en base b de
n.
L’avant dernier chiffre de l’écriture en base b de n sera donné par le
le reste de la division euclidienne de q (q:=iquo(n,b)) par b.
On fait donc une boucle en remplacant n par q (n:=iquo(n,b))
tant que n ≥ b en mettant à chaque étape r:=irem(n,b) au
début de la liste qui doit renvoyer le résultat.
On écrit la fonction itérative ecritu
qui renvoie la liste des chiffres de n en base b :
ecritu(n,b):={
//n est en base 10 et b<=10, ecrit est une fonction iterative
//renvoie la liste des caracteres de l'ecriture de n en base b
local L;
L:=[];
while (n>=b){
L:=concat([irem(n,b)],L);
n:=iquo(n,b);
}
L:=concat([n],L);
return(L);
}
- Version récursive
Si n<b, l’écriture en base b est la même que
l’écriture en base dix et est n.
Si n ≥ b, l’écriture en base b de n est formée par
l’écriture en base b de q suivi de r, lorsque q et r sont le
quotient et le reste de la division euclidienne de n par b
(n=b*q+r avec 0≤ r<b).
On écrit la fonction récursive ecritur
qui renvoie la liste des chiffres de n en base b :
ecritur(n,b):={
//n est en base 10 et b<=10, ecritur est recursive
//renvoie la liste des caracteres de l'ecriture de n en base b
if (n>=b)
return(concat(ecritur(iquo(n,b),b),irem(n,b)));
else
return([n]);
}
On choisit 36 symboles pour écrire un nombre :
les 10 chiffres 0,1..9 et les 26 lettres majuscules A,B,..,Z.
On transforme tout nombre positif ou nul n (n<b) en un caractère :
ce caractére est soit un chiffre (si n<10) soit une lettre (A,B...Z)
(si 9<n<36).
chiffre(n,b):={
//transforme n (0<=n<b) en son caractere ds la base b
if (n>9)
n:=char(n+55);
else
n:=char(48+n);
return(n);
}
On obtient alors la fonction itérative ecritu:
ecritu(n,b):={
//n est en base 10 et b<=36, ecritu est une fonction iterative
//renvoie la liste des caracteres de l'ecriture de n en base b
local L,r,rc;
L:=[];
while (n>=b){
r:=irem(n,b);
rc:=chiffre(r,b);
L:=concat([rc],L);
n:=iquo(n,b);
}
n:=chiffre(n,b);
L:=concat([n],L);
return(L);
}
- Version recursive
ecriture(n,b):={
//n est en base 10 et b<=36, ecriture est une fonction recursive
//renvoie la liste des caracteres de l'ecriture de n en base b
local r,rc;
if (n>=b){
r:=irem(n,b);
rc:=chiffre(r,b);
return(append(ecriture(iquo(n,b),b),rc));
}
else {
return([chiffre(n,b)]);
}
}
En utilisant la notion de séquence on peut aussi écrire :
ecrit(n,b):= {
//renvoie la sequence des chiffres de n dans la base b
local m,u,cu;
m:=(NULL);
while(n!=0){
u:=(irem(n,b));
if (u>9) {
cu:=(char(u+55));
}
else {
cu:=(char(u+48));
};
m:=(cu,m);
n:=(iquo(n,b));
};
return(m);
}
Il faut convertir ici chaque caractère en sa valeur (on convertit le
caractère contenu dans m en le nombre nm).
Si m=(c0,c1,c2,c3) alors n=c0*b3+c1*b2+c2*b+c3.
On calcule n en se servant de l’algorithme de Hörner (cf 8.15).
En effet le calcul de n=c0*b3+c1*b2+c2*b+c3 revient à calculer la
valeur du polynôme P(x)=c0*x3+c1*x2+c2*x+c3 pour x=b.
n va contenir successivement :
0 (n:=0) puis
c0 (n:=n*b+c0) puis
c0*b+c1 (n:=n*b+c1) puis
c0*b2+c1*b+c2=(c0*b+c1)*b+c2 (n:=n*b+c2) et enfin
c0*b3+c1*b2+c2*b+c3 (n:=n*b+c3).
On écrit donc la fonction nombre dans Xcas :
nombre(m,b):={
local s,k,am,nm,n;
s:=(size(m));
n:=(0);
k:=(0);
if (s!=0) {
while(k<s){
am:=(asc(m[k])[0]);
if (am>64) {
nm:=(am-55);
}
else {
nm:=(am-48);
};
if (nm>(b-1)) {
return("erreur");
}
n:=(n*b+nm);
k:=(k+1);
};
}
return(n);
}
On veut afficher en base dix la suite ordonnée des entiers dont l’écriture en base trois ne comporte que des 0 ou des 1 (pas de 2).
pasde21(n):={
local L,j,J,p;
L:=[0];
p:=1;
j:=1;
tantque p<n faire
J:=convert(j,base,3);
si not(est_element(2,J)) alors
L:= append(L,j);
p:=p+1;
fsi;
j:=j+1;
ftantque;
retourne L;
}
:;
pasde22(n):={
local J,a,p,L;
L:=[];
pour p de 0 jusque n-1 faire
J:=convert(p,base,2);
a:=convert(J,base,3);
L:=append(L,a)
fpour
retourne L;
}:;
pasde23(n):={
local L,p;
L:=[0];
p:=1;
tantque p<n faire
L:=mat2list(map(L,x->[x*3,x*3+1]));
p:=2*p;
ftantque;
L:=mid(L,0,n);
retourne L;
}
:;
Dans le programme ci-dessus la liste L est recréée à chaque
itération, il est donc préférable de modifier ce programme pour qu’à
chaque itération on ne calcule que les nouveaux termes dans la liste
LA et ce sont ces nouveaux termes qui créront les termes suivants...
pasde23b(n):={
local L,p,LA;
L:=[0,1];
LA:=[1];
p:=2;
tantque p<n faire
LA:=mat2list(map(LA,x->[x*3,x*3+1]));
L:=concat(L,LA);
p:=2*p;
ftantque;
L:=mid(L,0,n);
retourne L;
}
:;
À la fin de la boucle tantque, L a 2j=p≥ n éléments :
il faut raccourcir la liste L (L:=mid(L,0,n)) et on calcule des
termes pour rien...On modifie encore le programme, mais comme la liste LA
engendre les termes 2 par 2, on calcule quand même un terme de trop si
n est impair.pasde23t(n):={
local L,p,LA;
L:=[0,1];
LA:=[1];
p:=2;
tantque 2p<=n faire
LA:=mat2list(map(LA,x->[x*3,x*3+1]));
L:=concat(L,LA);
p:=2*p;
ftantque;
LA:=mat2list(map(mid(LA,0,iquo(n-p+1,2)),x->[x*3,x*3+1]));
L:=concat(L,LA);
retourne mid(L,0,n);
}
:;
pasde24(n):={
local L,j,p,puis3j;
L:=[0];
j:=0;
p:=1;
puis3j:=1;
tantque p<n faire
L:=concat(L,L+[puis3j$p]);
//L:=concat(L,map(L,x->x+puis3j));
j:=j+1;
puis3j:=3*puis3j;
p:=2*p;
ftantque;
L:=mid(L,0,n);
retourne L;
}
:;
À la fin de la boucle tantque, L a 2j=p>=n éléments : il
faut donc raccourcir la liste L (L:=mid(L,0,n)) et on calcule des
termes pour rien...On modifie donc le programme :
pasde24b(n):={
local L,j,p,puis3j;
L:=[0];
j:=0;
p:=1;
puis3j:=1;
tantque 2*p<=n faire
L:=concat(L,L+[puis3j$p]);
j:=j+1;
puis3j:=3*puis3j;
p:=2*p;
ftantque;
L:=concat(L,mid(L,0,n-p)+[puis3j$(n-p)]);;
retourne L;
}:;
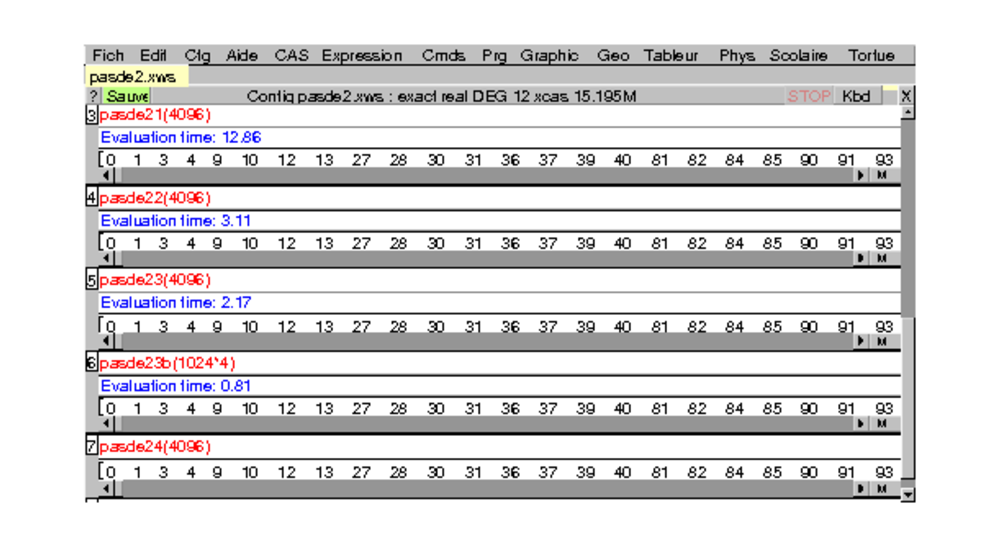
Ce qui montre que le dernier algorithme est le meilleur...
Soient deux entiers p,q, premiers entre eux tel que q<p. On veut écrire un entier n sous la forme :
| n= |
| nk( |
| )k avec nk<p |
On définit la suite :
u(0)=n, u(1)=iquo(u(0),p)*q, u(k+1)=iquo(u(k),p)*q
u est une suite décroissante donc il existe s tel que u(s)=0.
On a :
u(0)=iquo(u(0,p)*p+irem(u(0),p)=u(1)*p/q+irem(u(0),p)
u(1)=iquo(u(1,p)*p+irem(u(1),p)=u(2)*p/q+irem(u(1),p)
On pose n0=irem(u(0),p)
Donc :
qs−1u(0)=u(1)*p*qs−2+qs−1n0
et par itération :
pqs−2u(1)=u(2)p2qs−3+pqs−2n1 avec n1==irem(u(1),p)
...
qs−1u(0)=∑k=0s−1pkqs−k−1nk
ou encore :
n=u(0)=∑k=0s−1pkq−knk
Cette écriture est unique : on raisonne par récurrencesur n.
Le développement est unique pour tous les n<p.
Si il y a unicité pour tous les entiers m<n alors si on a 2 développements
de n :
n==∑k=0s−1pkq−kak et n==∑k=0s−1pkq−kbk
puisque n=a0+p*∑k=1s−1pk−1q−kak=b0+p*∑k=1s−1pk−1q−kbk= on en déduit que a0=b0=irem(n,p) et on applique
l’hypothèse de récurrence à iquo(n,p)*q qui est strictement inférieur à n.
On écrit le programme dev qui renvoie la liste de dimension s :
[n0,n1..ns−1] et le programme verif qui effectue la vérification.
dev(n,p,q):={
local L,s,u;
si gcd(p,q)!=1 ou q>p-1 alors return "erreur"; fsi;
L:=NULL;
si n<p alors return n; fsi;
s:=n;
tantque s>0 faire
u:=irem(s,p);
s:=iquo(s,p)*q;
L:=L,u;
}
return [L];
}
:;
verif(L,p,q):={
local n,s,k;
n:=L[0];
s:=size(L);
pour k de 1 jusque s-1 faire
n:=n+L[k]*(p/q)^k;
fpour;
return n;
}:;
On tape :
L:=dev(33,3,2)
On obtient :
[0,1,2,2,1,2]
On tape :
verif(L,3,2)
On obtient :
33
On tape :
L:=dev(133,13,8)
On obtient :
[3,2,9,11,8]
On tape :
verif(L,13,8)
On obtient :
133
Soit un polynôme P donné sous la forme d’une liste l formée par
les coefficients de P selon les puissances décroissantes.
hornerl(l,a) renvoie une liste formée par la valeur val
du polynôme en x=a et par la liste lq des coefficients selon les
puissances décroissantes du quotient Q(x) de P(x) par (x−a).
On a :
P(a)=l[0]*ap+l[1]*ap-1+...+l[p]=
l[p]+a*(l[p-1]+a*(l[p-2]+...+a*(l[1]+a*l[0])))
P(x)=l[0]*xp+l[1]*xp-1+...+l[p]=
(x-a)*(lq[0]*xp-1+...lq[p-1])+val
donc val=P(a)
et p=s-1 si s est la longueur de la liste l donc :
lq[0]=l[0]
lq[1]=a*lq[0]+l[1]
lq[j]=a*lq[j-1]+l[j]
....
val=a*lq[p-1]+l[p]
hornerl(l,a):={
local s,val,lq,j;
s:=size(l);
//on traite les polys constants (de degre=0)
if (s==1) {return [l[0],[0]]};
// si s>1
lq:=[];
val:=0;
for (j:=0;j<s-1;j++) {
val:=val*a+l[j];
lq:=append(lq,val);
}
val:=val*a+l[s-1];
return([val,lq]);
};
On tape :
hornerl([1,2,4],12)
On obtient :
[172,[1,14]]
ce qui veut dire que :
x2+2x+4=(x+14)(x−12)+172
Si le polynôme est donné avec son écriture habituelle.
Pour utiliser la fonction précédente on a alors besoin des deux
fonctions :
symb2poly qui transforme un polynôme en la liste de ses
coefficients selon les puissances décroissantes.
poly2symb qui transforme une liste en l’écriture habituelle du
polynôme ayant cette pour coefficients selon les puissances décroissantes.
hornerp(p,a,x):={
//ne marche pas pour les polys constants (de degre=0)
local l,val,lh;
l:=symb2poly(p,x);
lh:=hornerl(l,a);
p:=poly2symb(lh[1],x);
val:=lh[0];
return([val,p]);
};
On tape :
hornerp(x^2+2x+4,12,x)
On obtient :
172,x+14
On tape :
hornerp(y^2+2y+4,12,y)
On obtient :
172,y+14
Dans Xcas, il existe la fonction horner qui calcule selon la
méthode de Hörner la valeur d’un polynôme (donné sous forme de liste
ou par son expression) en un point :
On tape :
horner(x^2+2x+4,12)
On obtient :
172
On tape :
horner(y^2+2y+4,12,y)
On obtient :
172
On tape :
horner([1,2,4],12)
On obtient :
172
Trouver le plus petit entier positif n, tel que n, 2n, 3n, 4n, 5n,
6n contiennent exactement les mêmes chiffres.
On tape la fonction booléenne qui teste si les entiers n et m ont des
chiffres identiques.
On se sert de la fonction string qui transforme un entier en une chaine de caractères, puis on
transforme cette chaine en la liste de ses caractères ou en son code de Ascii, puis on
trie cette liste.
On tape :
chiffreid(n,m):={
local S1,S2,s1,s2,L1,L2,k;
S1:=string(n);s1:=size(S1);
S2:=string(m);s2:=size(S2);
si s1!=s2 alors retourne faux; fsi;
L1:=[sort(S1[k]$(k=0..s1-1))];
L2:=[sort(S2[k]$(k=0..s1-1))];
retourne L1==L2;
}:;
ou
chiffreid(n,m):={
local S1,S2,s1,s2,L1,L2,k;
S1:=string(n);s1:=size(S1);
S2:=string(m);s2:=size(S2);
si s1!=s2 alors retourne faux; fsi;
L1:=sort(asc(S1));
L2:=sort(asc(S2));
retourne L1==L2;
}:;
On tape la fonction booléenne qui teste si les entiers n, 2n, 3n, 4n,
5n, 6n ont des chiffres identiques. Si cela est le cas on
sait que n est divisible par 3 puisque la somme des chiffres de n est égale la somme des chiffres
de 3n.
On tape :
chiffreid16(n):={
local k;
si irem(n,3)!=0 alors retourne faux; fsi;
pour k de 6 jusque 2 pas -1 faire
si chiffreid(n,k*n)==faux alors retourne faux fsi;
fpour;
retourne vrai;
}:;
On tape la fonction qui renvoie le plus petit entier positif n, tel que n,
2n, 3n, 4n, 5n, 6n contiennent exactement les mêmes chiffres.
On tape :
ppchiffreid():={
local n;
n:=3;
tantque chiffreid16(n)==faux faire
n:=n+3;
ftantque;
retourne n;
}:;
On tape :
ppchiffreid()
On obtient :
142857
On vérifie :
On tape :
n:=142857;2*n;3*n;4*n;5*n;6*n
On obtient ;
142857,285714,428571,571428,714285,857142
On peut changer le programme ci-dessus pour savoir qui est le n suivant en
initialisant n à 142860. On trouve alors 1428570.
Puis on change à nouveau le programme ci-dessus pour savoir qui est le n suivant en
initialisant n à 1428573. On trouve alors 1429857.
Puis par curiosité, on cherche le suivant (mais c’est long !), on trouve 14285700.
On a donc le début de cette suite :
142857, 1428570, 1429857, 14285700, 14298570
On va écrire la fonction récursive estdivpoly qui a comme arguments,
deux polynômes A et B écrits sous forme symbolique et qui
renverra 1 si A est divisible par B et 0 sinon.
On rappelle que degree(A) renvoie le degré de A et que
valuation(A) renvoie la valuation de A
(la plus petite puissance de A).
Pour Savoir si A est divisible par B, on s’interesse aux termes de
plus haut degré et de plus bas degré de A et B : c’est à dire
qu’a chaque étape on essaye de faire la division par les 2 bouts ....
Par exemple si :
A=x^3+2*x-3 et B=x^2+x on sait que A n’est pas
divisible par B car -3 n’est pas divisible par x,
ou encore si :
A=x^3+2*x^2 et B=x^2+1 on sait que A
n’est pas divisible par B car le quotient aurait pour degré
3-2=1 et pour valuation 2-0=2, ce qui est impossible 1<2 (le
degré n’peut pas être inférieur à la valuation.
estdivpoly(A,B):={
local da,db,va,vb,dq,vq,dva,dvb,dvq,Q,Ca,Cb;
da:=degree(A);
va:=valuation(A);
dva:=da-va;
db:=degree(B);
vb:=valuation(B);
dvb:=db-vb;
if (A==0) then return 1;end_if;
if ((da<db) or (va<vb)) then return 0;end_if;
if ((dva==0) and (dvb>0)) then return 0;end_if;
if ((dva>=0) and (dvb==0)) then return 1;end_if;
Cb:=coeffs(B);
if ((dva>0) and (dvb>0)) then
dq:=da-db;
vq:=va-vb;
dvq:=dq-vq;
if (dvq<0) then return 0;end_if;
Ca:=coeffs(A);
Q:=Ca[0]/Cb[0]*x^(dq);
if (dvq==0) then
A:=normal(A-B*Q);
else
Q:=Q+Ca[dva]/Cb[dvb]*x^(vq);
A:=normal(A-B*Q);
end_if;
da:=degree(A);
va:=valuation(A);
end_if;
return estdivpoly(A,B);
};
On tape :
A:=normal((x^4-x^3+x^2-1)*(x^5-x^3+x^2-1)
puis,
estdivpoly(A,x^4-x^3+x^2-1)
On obtient :
1
Lorsque A est divisible par B on peut en modifiant le programme
précédent avoir facilement le quotient exact de A par B.
On écrit la fonction récursive quoexpoly qui a trois arguments,
deux polynômes A et B écrits sous forme symbolique et 0.
quoexpoly renverra 1,Q si A=B*Q et 0 sinon.
Puis on écrit la fonction quopoly(A,B) qui est égale à
quoexpoly(A,B,0).
quoexpoly(A,B,SQ):={
local da,db,va,vb,dq,vq,dva,dvb,dvq,Q,Ca,Cb;
da:=degree(A);
va:=valuation(A);
dva:=da-va;
db:=degree(B);
vb:=valuation(B);
dvb:=db-vb;
if (A==0) then return 1,SQ;end_if;
if ((da<db) or (va<vb)) then return 0;end_if;
if ((dva==0) and (dvb>0)) then return 0;end_if;
if ((dva>=0) and (dvb==0)) then return 1,normal(SQ+normal(A/B));end_if;
Cb:=coeffs(B);
if ((dva>0) and (dvb>0)) then
dq:=da-db;
vq:=va-vb;
dvq:=dq-vq;
if (dvq<0) then return 0;end_if;
Ca:=coeffs(A);
Q:=Ca[0]/Cb[0]*x^(dq);
if (dvq==0) then
A:=normal(A-B*Q);
SQ:=normal(SQ+Q);
else
Q:=Q+Ca[dva]/Cb[dvb]*x^(vq);
A:=normal(A-B*Q);
SQ:=normal(SQ+Q);
end_if;
da:=degree(A);
va:=valuation(A);
end_if;
return quoexpoly(A,B,SQ);
};
estquopoly(A,B):=quoexpoly(A,B,0);
On tape :
A:=normal((x^4-x^3+x^2-1)*(x^5-x^3+x^2-1)
puis,
estquopoly(A,x^4-x^3+x^2-1)
On obtient :
1,x^5-x^3+x^2-1
Pour rendre plus facile la lecture d’un grand nombre entier, on veut l’afficher par tranches, c’est à dire selon une chaîne de caractères constituées par les p premiers chiffres du nombre et d’un espace, puis les p suivants etc... On écrit le programme qui va afficher le nombre n par tranches de p chiffres:
affichen(n,p):={
local reste,result,s;
result:="";
while (n>10^p) {
//on transforme irem(n,10^p) en une chaine
reste:=cat(irem(n,10^p),"");
s:=size(reste);
//on ajoute l'espace et les zeros qui manquent
reste:=cat(" ",op(newList(p-s)),reste);
n:=iquo(n,10^p);
//on concatene reste avec result
result:=cat(reste,result);
}
reste:=cat(n);
return cat(reste,result);
};
On tape :
affichen(1234567,3)
On obtient :
"1 234 567"
Pour avoir la transformation inverse, on va transformer une chaîne
comportant des chiffres et un autre caractère (par exemple un espace) en un
nombre entier.
On écrit le programme :
enleve(chn,ch):={
local l,s;
s:=length(chn)-1;
//on transforme chn en une liste de ces lettres
//puis, on enleve le caractere ch de cette liste
l:=remove(x->(ord(x)==ord(ch)),seq(chn[k],k,0,s));
//on transforme la liste en chaine
return expr(char(ord(l)));
};
On peut aussi remplacer la dernière ligne :
return char(ord(l))
(ord(l) transforme la liste de caractères en la liste de leurs codes
ascii et char transforme la liste des codes ascii en une chaîne).
par :
return cat(op(l))
car op(l) transforme la liste en une séquence et cat
concatène les éléments de cette séquence en une chaîne.
On tape :
enleve("1 234 567"," ")
On obtient :
1234567
Pour rendre plus facile la lecture d’un nombre décimal de [0,1[, on veut l’afficher par tranches, c’est à dire selon une chaîne de caractères constituées par les p premières décimales du nombre et d’un espace, puis les p suivants etc... On suppose que l’écriture de d comporte un point (.) suivi des décimales et ne comporte pas d’exposant (pas de e4)
On écrit le programme qui va afficher le nombre d par tranches de p chiffres:
affiched(d,p):={
local deb,result;
//on suppose 0<=d<1
d:=cat(d,"");
if (d[0]=="0") {d:=tail(d);}
if (expr(tail(d))<10^p){return d;}
deb:=mid(d,0,p+1);
result:=cat(deb," ");
d:=mid(d,p+1);
while (expr(d)>10^p) {
deb:=mid(d,0,p);
result:=cat(result,deb," ");
d:=mid(d,p);
}
return cat(result,d);
};
On tape :
affiched(0.1234567,3)
On obtient :
".123 456 7"
Remarque
La commande enleve(affiched(d,3)," ") permet encore de retrouver d.
enleve(chn,ch):={
local l,s;
s:=length(chn)-1;
//on transforme chn en une liste de ces lettres
//puis, on enleve le caractere ch de cette liste
l:=remove(x->(ord(x)==ord(ch)),seq(chn[k],k,0,s));
//on transforme la liste en chaine
return expr(char(ord(l)));
};
Pour rendre plus facile la lecture d’un nombre décimal, on veut
l’afficher par tranches, c’est à dire selon une chaîne de caractères
constituées par sa partie entière écrite par tranches de p chiffres,
puis ses p premières décimales du nombre et d’un espace, puis les p
suivants etc...
Ici, le nombre f peut comporter un exposant à la fin de son écriture.
On écrit le programme qui va afficher le nombre décimal f par tranches
de p chiffres :
//pour les flottants f utiliser affichef
// appelle affichen et affiched
//par exemple affichef(1234.12345,3)
affichef(f,p):={
local deb,result,s,indicep,fn,fd,indicee;
//on suppose f>1
f:=cat(f);
s:=size(f)-1;
indicep:=member(".",seq(f[k],k,0,s));
indicee:=member("e",seq(f[k],k,0,s));
if (indicep!=0) {
fn:=mid(f,0,indicep-1);
fd:=mid(f,indicep-1);
if (indicee!=0) {
return affichen(expr(fn),p)+affiched(expr(mid(fd,0,
indicee-1)),p)+mid(fd,indicee-1);}
return affichen(expr(fn),p)+affiched(expr(fd),p)
}
return affichen(expr(f),p);
};
On tape :
affichef(1234567.1234567,3)
On obtient (pour 12 chiffres significatifs) :
"1 234 567.123 46"
On obtient (pour 14 chiffres significatifs) :
"1 234 567.123 456 7"
On obtient (pour 15 chiffres significatifs) :
"0.123 456 712 345 670 0*e7"
Remarque
La commande enleve(affichef(q,3)," ") permet encore de retrouver q.
enleve(chn,ch):={
local l,s;
s:=length(chn)-1;
//on transforme chn en une liste de ces lettres
//puis, on enleve le caractere ch de cette liste
l:=remove(x->(ord(x)==ord(ch)),seq(chn[k],k,0,s));
//on transforme la liste en chaine
return expr(char(ord(l)));
};
Pour obtenir la partie entière et le développement décimal de
a/b, on va construire deux listes :
L1 la liste des restes et L2
la liste des quotients obtenus par l’algorithme de la potence .
On met le quotient q dans L1 et le reste r dans L2.
On a ainsi, la partie entière de a/b dans L1
et comme a/b=q+r/b on cherche la partie entière de 10*r/b qui va rallonger L1 etc...
Si on veut, par exemple, le développement décimale de
278/31 on cherche :
le quotient q=8 et le reste r=30 de la divison euclidienne de 278 par 31.
La partie entière est donc 8 et, on met 8L1 .
Pour avoir la partie décimale de 278/31, on fait
comme à la main l’algorithme de
la potence : on multiplie le reste trouvé par 10, on trouve 300
puis on le divise par 31 : le quotient trouvé 9 est
rajouté à L1 et le reste est rajouté à L2 etc...
On écrit la fonction potence qui renvoie dans la première liste
la partie entière puis les n décimales de a/b et dans la
deuxième liste les restes successifs obtenus.
potence(a,b,n):={
local L1,L2,k;
b0:=b;
b:=iquo(a,b0);
a:=irem(a,b0);
L1:=[b];
L2:=[a];
for (k:=1;k<=n and a!=0;k++){
b:=iquo(a*10,b0);
a:=irem(a*10,b0);
L2:=append(L2,a);
L1:=append(L1,b);
};
return([L1,L2]);
};
En exécutant potence(278,31,20), on lit la partie entière de
278/31 et les chiffres de sa partie décimale dans la
première liste et, la suite des restes dans la deuxième liste.
Exercice
Écrire la partie entière et le développement décimal de :
a=11/7, b=15/14 et
c=17/28.
Calculer a−b et a−c
et donner leur partie entière et leur
développement décimal.
Que remarqez-vous ?
Exercice
Comment modifier L1 et L2 pour que les chiffres de la
partie décimale de a/b se lisent par paquet de trois
chiffres dans L1.
Avec l’exemple 278/31 on veut obtenir :
L1=[8,967,741,935 ...]
Tester votre modification pour 349/1332.
Que remarquez vous ?
division(a,b,n,t) donne la partie entière suivie de n paquets de t décimales (i.e. des n*t premières décimales) de a/b.
division(a,b,n,t):={
local L1,L2,p,q,r,k;
L1:=[iquo(a,b)];
r:=irem(a,b);
for (k:=1;k<=n and r!=0;k++) {
q:=iquo(r*10^t,b);
//10^(p-1)<= q <10^p
if (q==0) {p:=1} else {p:=floor(ln(q)/ln(10)+1)};
//on complete par des zeros pour avoir un paquet de t decimales
for (j:=p+1;j<=t;j++){
L1:=append(L1,0);
}
L1:=append(L1,q);
r:=irem(r*10^t,b);
}
return(L1,r);
};
On tape pour avoir 5*6=30 decimales :
division(2669,201,6,5)
On obtient :
[13,27860,69651,74129,35323,38308,45771],29
Trouver un nombre rationnel qui s’écrit :
0.123123123123... se terminant par une suite illimitée de 123.
Trouver un nombre rationnel qui s’écrit :
0.120123123123... se terminant par une suite illimitée de 123.
Écrire un programme qui permet de trouver un nombre rationnel à partir
d’un développement décimal périodique.
Réponse :
On écrit la fonction rationnel qui a comme le paramètre deux listes
l1 et l2 :
- l1 désigne la partie non périodique de ce développement et
l1[0] désigne la partie entière.
- l2 représente un développement décimal périodique.
rationnel(l1,l2):={
//l1 et l2 sont non vides
local pui,s1,s2,n,p,np,pui,k;
pui:=10;
s2:=size(l2);
n:=l2[0];
for (k:=1;k<s2;k++){
pui:=pui*10;
n:=n*10+l2[k];
}
// 0.123123...=123/999
p:=n/(pui-1);
//np partie non periodique
np:=l1[0];
s1:=size(l1);
pui:=1;
for (k:=1;k<s1;k++){
pui:=pui*10;
np:=np+l1[k]/pui;
}
//pui=10^(s1-1)
return(np+p/pui);
};
Théorème1 Si a et b sont des entiers naturels premiers entre eux, alors il existe des entiers naturels a0,a1,...,an (0 ≤ n) tels que :
| =a0+ |
|
Si b≤ a les aj sont non nuls et, si a<b alors a0=0 et les autres
aj sont non nuls.
Définition
On pose alors a/b=(a0,a1,...an) et on dit que
(a0,a1,...an)
est une fraction continue : c’est le développement en fraction continue de
a/b.
Remarque si b≤ a et si a/b=(a0,a1,...an)
alors b/a=(0,a0,a1,...an).
Réduite et reste
On dit que la fraction Pp/Qp égale à la
fraction continue (a0,a1,...ap), où p≤ n, est la réduite de
rang p de a/b ou que c’est le développement en
fraction continue d’ordre p de a/b.
On dit que
r=(0,ap+1,..,an) est le reste du développement d’ordre p (r<1)
et on a a/b=(a0,a1,...ap+r)=(a0,a1,...ap,1/r),
a/b=a0+1/a1+1/a2+1/...ap−3+1/ap−2+1/ap+r.
Si Pp/Qp égale à la
fraction continue (a0,a1,...ap), où p≤ n, est la réduite de
rang p de a/b=(a0,a1,...an), on a :
P0=a0
Q0=1
P1=a0*a1+1
Q1=a1
Pp=Pp−1*ap+Pp−2
Qp=Qp−1*ap+Qp−2
En effet on le montre par récurrence :
P2/Q2=a0+a2/(a1a2+1) donc
P2=a2(a0+a1+1)+a0=a2P1+P0 et
Q2=a2a1+1=a2Q1+Q0
(a0,a1,...,ap+1/ap+1)=Pp+1/Qp+1 donc
Pp+1/Qp+1=((ap+1/ap+1)Pp−1+Pp−2)/((ap+1/ap+1)Qp−1+Qp−2)
Pp+1=ap+1(apPp−1+Pp−2)+Pp−1=ap+1Pp+Pp−1 et
Qp+1=ap+1(apQp−1+Qp−2)+Qp−1=ap+1Qp+Qp−1
Le programme f2dfc :
On veut transformer une fraction en son développement en fraction continue :
f2dfc(a/b)=(a0, a1,...an).
Pour obtenir le développement en fraction continue de a/b, on cherche le
quotient q et le reste r de la division euclidienne de a par b.
On a : q=a0 et a/b=a0+r/b=a0+1/(b/r) et, on continue en cherchant
la partie entiére de b/r qui sera a1....On reconnait
l’algorithme d’Euclide : la suite (a0, a1,...an) est donc la suite
des quotients de l ’algorithme d’Euclide.
On écrit le programme :
f2dfc(fract):={
local r,q,l,lres,a,b;
l:=f2nd(fract);
a:=l[0];
b:=l[1];
lres:=[];
while (b>0) {
q:=iquo(a,b)
lres:=concat(lres,q);
r:=irem(a,b);
a:=b;
b:=r:
}
return lres;
}
On tape :
f2dfc(2599/357)
On obtient :
[7,3,1,1,3,14]
Le programme f2reduites d’un rationnel et l’identité de Bézout :
On veut obtenir la suite des réduites de a/b.
L’algorithme pour obtenir les réduites ressemble beaucoup à l’algorithme
utilisé pour obtenir les coefficients u et v de l’identité de
Bézout (cf 8.3.5).
En effet on a :
P0=a0=a0*1+0 alors que v0=0
Q0=1=a0*0+1 alors que u0=1
P1=a0a1+1=P0*a1+1 alors que v1=1
Q1=a1=a1*Q0+0 alors que u1=0
Pp=Pp−1*ap+Pp−2 alors que vp=vp−2−ap−2vp−1
Qp=Qp−1*ap+Qp−2 alors que up=up−2−ap−2up−1
Ainsi :
P0=0+a0*1=v0−a0*v1=−v2
P1=1+P0*a1=v1−v2*a1=v3
P2=P0+P1*a2=−v2+v3*a2=−(v2−v3*a2)=−v4
On a donc pour tout p ≥ 0, si ap est la suite des quotients de
l’algorithme d’Euclide :
Qp=Qp−1*ap+Qp−2 avec Q−2=1=u0 et Q−1=0=u1 et,
Pp=Pp−1*ap+Pp−2 avec P−2=0=v0 et P−1=1=v1
Dans l’algorithme de Bézout on a :
up=−up−1*ap−2+up−2 et vp=−vp−1*ap−2+vp−2
Q0=0+u2 donc Q1=−u3, Q2=u4 etc...donc Qn=(−1)nun+2 et,
P0=−v2+0 donc P1=v3, P2=−v4 etc...donc Pn=(−1)n+1vn+2.
Donc Pn/Qn=−vn+2/un+2
Donc la suite Qj/Pj est donc la suite des −u/v.
On écrit le programme (calqué sur le programme Bezout avec les
listes) qui transforme une fraction en son développement en fraction continue
suivi de la suite de ces réduites :
f2reduites(fract):={
local lr,q,l,lres,la,lb,lq;
l:=f2nd(fract);
//a:=l[0];b:=l[1];
la:=[1,0,l[0]];
lb:=[0,1,l[1]];
lq:=[];
lres:=[];
while (lb[2]>0) {
q:=iquo(la[2],lb[2])
lr:=la-q*lb;
lq:=concat(lq,q);
lres:=concat(lres,-lr[1]/lr[0]);
la:=lb;
lb:=lr;
}
return lq,lres;
}
On tape :
f2reduites(2599/357)
On obtient :
[7,3,1,1,3,14],[7,22/3,29/4,51/7,182/25,2599/357]
Remarque :
On ne peut pas remplacer :
lr:=la-q*lb;
lres:=concat(lres,-lr[1]/lr[0])
par :
lr:=la+q*lb;
lres:=concat(lres,lr[1]/lr[0]);
car alors lr n’est plus la suite des restes !
Le programme dfc2reduites d’un rationnel et l’identité de Bézout:
On veut obtenir la suite des réduites d’une liste l (qui sera par exemple
le développement en fraction continue d’un rationnel a/b)
On écrit le programme (calqué sur le programme Bezout sans les
listes) qui transforme une liste [a0,a1,..an] en la
liste [a0,a0+1/a1,....,(a0+1/a1+1/...+1/an−1+1/an)] :
dfc2reduites(l):={
local s,p0,q0,p1,q1,p,q,lres,j;
s:=size(l);
lres:=[];
p0:=0;
p1:=1;
q0:=1;
q1:=0;
for (j:=0;j<s;j++){
p:=p0+l[j]*p1;
q:=q0+l[j]*q1;
lres:=concat(lres,p/q);
p0:=p1;
q0:=q1;
p1:=p;
q1:=q;
}
return lres;
}
On remarquera que :
-la suite des P est initialisée par
p0 et p1, puis, quand j=0, on fait le calcul de P0 qui est mis dans
p, puis, quand j=1 on fait
le calcul de P1 qui est mis dans p, etc... et que
- la suite des Q est initialisée par :
q0 et q1, puis, quand j=0 on fait le calcul de Q0 qui est mis dans
q, quand j=1, on fait
le calcul de Q1 est mis dans q, etc...
On tape :
dfc2reduites([7,3,1,1,3,14])
On obtient :
[7,22/3,29/4,51/7,182/25,2599/357]
Théorème2 Si α est un nombre réel non rationnel, alors il existe des entiers naturels non nuls a0,a1,...,an et un réel β<1 tels que :
| α=a0+ |
|
On dit que (a0,a1,...an) est le développement en fraction continue
d’ordre n+1 de α et que β est le reste de ce développement.
Un rationnel a un développement en fraction continue fini et
réciproquement, un développement en fraction continue fini représente
un rationnel.
Un réel non rationnel a un développement en fraction continue infini.
Si α est un nombre quadratique (i.e. α est racine d’une
équation du second degré), α a un développement en fraction
continue périodique et réciproquement, un développement en fraction
continue périodique représente un nombre quadratique.
On va écrire deux fonctions r2dfc et dfc2r.
r2dfc(alpha,n) qui transforme un réel alpha en son
développement en fraction continue et qui renvoie deux listes, soit :
- [a0,a1...ap],[] avec p ≤ n où les aj sont
des entiers, la deuxième liste est
vide et la première liste est le développement en fraction
continue de alpha (les aj sont des entiers et donc alpha
est une fraction)
- [a0,a1...an-1,b],[], la deuxième liste est vide et
la première liste est le développement en fraction
continue d’ordre n−1 de alpha suivi de b>1 (le reste est égal à
1/b), où les aj sont des entiers et b est un réel
plus grand que 1, soit,
- [a0,a1...ap],[ar,..ap] avec r≤ p < n
où les aj sont des entiers, la première liste est le
développement en fraction continue d’ordre p de alpha et
la deuxième liste représente la période de cedéveloppement en fraction
continue (les aj sont des entiers et donc alpha est un nombre
quadratique)
.
On remarquera dans le programme ci-dessous que :
a0=floor(alpha)=q remplace q:=iquo(a,b) lorsque
alpha=a/b
et que r=alpha-q remplace irem(a,b)/b lorsque
alpha=a/b
et donc que si r=alpha-q, a1=floor(1/r) etc...
Le problème ici est de pouvoir comparer alpha et q
c’est à dire savoir si r==0 et pour cela on est obligé de
faire les calculs avec beaucoup de décimales c’est à dire d’augmenter
le nombre de digits (on tape par exemple DIGITS:=30).
Il faut bien sûr repérer la période, pour cela on forme la liste
lr des restes successifs. La liste lq des parties entières
successives forme le début du développement en fraction continue.
r2dfc(alpha,n):={
local r,q,lq,lr,p,j;
q:=floor(alpha);
r:=normal(alpha-q);
lq:=[];
lr:=[];
for (j:=1;j<=n;j:=j+1) {
lq:=concat(lq,q);
if (r==0){return (lq,[]);}
p:=member(r,lr);
if (p) {return (lq,mid(lq,p)):}
lr:=concat(lr,r);
alpha:=normal(1/r);
q:=floor(alpha);
r:=normal(alpha-q);
}
return (concat(lq,alpha),[]);
};
On tape :
dfc2r(sqrt(2),1)
On obtient :
([1,sqrt(2)+1],[])
On tape :
dfc2r(sqrt(2),2)
On obtient :
([1,2],[2])
On tape :
dfc2r(pi),6
On obtient :
([3,7,15,1,292,1,(-33102*pi+103993)/(33215*pi-104348)],[])
Remarque
Le premier argument doit être un nombre exact, car sinon les calculs sont
faits en mode approché et le test r==0 n’est jamais réalisé...
On écrit la fonction réciproque de r2dfc qui à partir d’un
développement en fraction continue et d’un reste éventuel ou d’un
développement en fraction continue et d’une période éventuelle
renvoie un réel.
dfc2r(d,t) transforme en un réel, la liste d représente un
développement en fraction continue et la liste
t représente la période.
On remarquera que lorsque la liste
t n’est pas vide il faut déterminer le nombre 0<y<1 qui admet
cette liste périodique comme développement en fraction continue et
pour ce faire résoudre l’équation :
y=(0,t0,...tst-1+y)
le reste est alors y+ds-1 (s:=size(d)).
On écrit le programme :
dfc2r(d,t):={
local s,st,alpha,l,ap,k;
s:=size(d);
alpha:=d[s-1];
for (k:=s-2;k>=0;k:=k-1) {alpha:=normal(d[k]+1/alpha);}
if (t==[]) {return normal(alpha);}
st:=size(t);
purge(y);
ap:=t[st-1]+y;
for (k:=st-2;k>=0;k:=k-1) {ap:=normal(t[k]+1/ap);}
l:=solve(y=1/ap,y);
if (l[0]>0){y:=normal(l[0]);}else{y:=normal(l[1]);};
alpha:=d[s-1]+y;
for (k:=s-2;k>=0;k:=k-1) {alpha:=normal(d[k]+1/alpha);}
return(normal(a)lpha);
};
ou avec une écriture plus concise :
dfc2r(d,t):={
local s,st,alpha,l,ap,k;
s:=size(d);
st:=size(t);
if (st==0)
{y:=0;}
else
{purge(y);
ap:=t[st-1]+y;
for (k:=st-2;k>=0;k:=k-1) {ap:=normal(t[k]+1/ap);}
l:=solve(y=1/ap,y);
if (l[0]>0){y:=normal(l[0]);}else{y:=normal(l[1]);};
}
alpha:=d[s-1]+y;
for (k:=s-2;k>=0;k:=k-1) {alpha:=normal(d[k]+1/alpha);}
return(normal(alpha));
};
1/ Développement en fraction continue de :
1393/972,
1+√13 et
1-√13.
On a :
r2dfc(1393/972,3)=[1,2,3,130/31],[]
r2dfc(1393/972,7)=[1,2,3,4,5,6],[]
et on a bien :
r2dfc(130/31,3)=[4,5,6],[]
r2dfc(31/130,4)=[0,4,5,6],[]
On peut vérifier que :
dfc2r([1,2,3,4,5,6],[])=1393/972
dfc2r([1,2,3+31/130],[])=dfc2r([1,2,3,130/31],[])=1393/972
On a :
r2dfc(1+sqrt(13),3)=[4,1,1,(sqrt(13)+2)/3],[]
r2dfc(1+sqrt(13),6)=[4,1,1,1,1,6],[1,1,1,1,6]
r2dfc(1-sqrt(13),7)=[-3,2,1,1,6,1,1],[1,1,6,1,1]
2/ Trouver les réels qui ont comme développement en fraction continue :
[2,4,4,4,4,4....] (suite illimitée de 4) et
[1,1,1,1,1,1....] (suite illimitée de 1).
On a :
dfc2r([2,4],[4])=sqrt(5)
ou encore
dfc2r([2],[4])=sqrt(5)
On a :
dfc2r([1],[1])=(sqrt(5)+1)/2
Si alpha a comme développement en fraction continue
(a0,a1,....an....), la suite des réduites est la suite des
nombres rationnels ayant comme développement en fraction continue :
(a0),(a0,a1),..,(a0,a1....an),.... .
On écrit le programme permettant d’obtenir les p premières
réduites de alpha.
On écrit le programme reduiten (on recalcule les réduites sans
se servir des relations de récurrence) :
reduiten(alpha,p):={
local l,k,ld,lt,st,s,q,lred,redu;
ld:=r2dfc(alpha,p);
l:=ld[0];
s:= size(l);
if (s<p) {
lt:=ld[1];
st:=size(lt);
if (st!=0){
q:=iquo(p-s,st);
for (j:=0;j<=q; j++){
l:= concat(l,lt)
}
}
else {
p:=s;
}
}
lred:=[];
for (k:=1;k<=p;k++){
redu:=dfc2r(mid(l,0,k),[]);
lred:=append(lred,redu);
}
return (lred);
};
reduiten(sqrt(53),5)
On obtient :
[7,22/3,29/4,51/7,182/25]
On écrit maintenant le programme reduite permettant d’obtenir les
p premières réduites de alpha, en se servant de la fonction
dfc2reduites écrite auparavant et qui utilise les relations de
récurrence.
reduite(alpha,p):={
local l,ld,lt,st,s,q,lred;
ld:=r2dfc(alpha,p);
l:=ld[0];
s:= size(l);
if (s<p) {
lt:=ld[1];
st:=size(lt);
if (st!=0){
q:=iquo(p-s,st);
for (j:=0;j<=q; j++){
l:= concat(l,lt)
}
}
}
l:= mid(l,0,p);
lred:=dfc2reduites(l);
return lred;
}
On tape :
reduite(sqrt(53),5)
On obtient :
[7,22/3,29/4,51/7,182/25]
On tape :
reduite(11/3,2)
On obtient :
[3,4]
Si alpha a comme développement en fraction continue
(a0,a1,....an....), la suite des réduites "plus 1"
est la suite des nombres
rationnels ayant comme développement en fraction continue :
(a0+1),(a0,a1+1),..,(a0,a1....an+1),.... .
On écrit le programme permettant d’obtenir les p premières
réduites "plus 1" de alpha.
reduite1(alpha,p):={
local l,ld,lt,st,s,q,lred;
ld:=r2dfc(alpha,p);
l:=ld[0];
s:= size(l);
if (s<p) {
lt:=ld[1];
st:=size(lt);
if (st!=0){
q:=iquo(p-s,st);
for (j:=0;j<=q; j++){
l:= concat(l,lt)
}
}
}
l:= mid(l,0,p)+1;
lred:=dfc2reduites(l);
return lred;
}
Propriété des réduites de alpha :
Une réduite p/q approche alpha à moins de 1/q2 et si
s/t est la réduite plus 1 de même rang n on a :
- |p/q-s/t|<1/q2
- si n est pair p/q ≤ alpha ≤ r/s
- si n est impair r/s ≤ alpha ≤ p/q
- les réduites de rang pair et les réduites de rang impair forment
deux suites adjacentes qui convergent vers alpha
- les réduites plus 1 de rang pair et les réduites plus 1 de rang impair
forment deux suites adjacentes qui convergent vers alpha
Donc, si on pose :
lred:=reduite(alpha,10) et
lred1:=reduite1(alpha,10),
ces deux suites lred et lred1 fournissent un encadrement de
alpha plus précisément on a :
lred[0] ≤ lred1[1]≤..≤ lred[2p] ≤ lred1[2p+1]<alpha
alpha<lred[2p+1]≤ lred1[2p] ≤ ...≤ lred[1] ≤ lred1[0]
c’est à dire que l’encadrement fait avec 2 réduites successives de rang
p−1 et p est moins bon que l’encadrement fait avec la réduite de rang
p et la réduite plus 1 de rang p.
Exemple
On a :
r2dfc(sqrt(53),5)= [7,3,1,1,3,sqrt(53)+7],[]
dfc2r([7,3,1,1,3],[])=182/25
reduite(sqrt(53),5)[4]=182/25=7.28
reduite1(sqrt(53),5)[4]=233/32=7.28125
reduite(182/25,5)[4]=182/25=7.28
reduite1(182/25,5)[4]=233/32=7.28125
et donc 7.28<√53<7.28125
r2dfc(sqrt(53),6)= [7,3,1,1,3,14],[3,1,1,3,14]
dfc2r([7,3,1,1,3,14],[])=2599/357
reduite(sqrt(53),6)[5]=2599/357=7.28011204482
reduite1(sqrt(53),6)[5]=2781/382=7.28010471204
reduite(2599/357,5)[4]=2599/357=7.28011204482
reduite1(2599/357,5)[4]=2781/382=7.28010471204
et donc 7.28010471204<√53<7.28011204482
On a 1/3572=7.84627576521e−06 et 1/3822=6.8528823223e−06
La suite de Hamming est la suite des nombres entiers qui n’ont pour diviseurs
premiers que 2, 3 et 5.
Cette suite commence par : [2,3,4,5,6,8,9,10,12,15,16,18,20,24,25...]
On écrit tous les nombres de Hamming de 0 à n>0 et on barre les
nombres qui sont de la forme 2a*3b*5c avec a,b,c variant de 0 à un
nombre tel que 2a*3b*5c ≤ n: les nombres barrés (excepté 1)
sont les nombres de Hamming inférieurs à n>0.
Voici la fonction hamming(n) écrite en Xcas pour obtenir
les nombres de Hamming inférieurs à n>0.
hamming(n):={
local H,L,a,b,c,j,d;
L:=makelist(x->x,0,n);
//les nbres de Hamming sont 2^a*3^b*5^c
c:=0; b:=0;a:=0;
d:=1;
while (d<=n) {
while (d<=n){
while (d<=n) {
L[d]:=0;
//d:=5*d
c:=c+1;
d:=2^a*3^b*5^c;
}
c:=0;
b:=b+1;
//d:=2^a*3^b*5^c
d:=2^a*3^b;
}
//c:=0;
b:=0;
a:=a+1;
//d:=2^a*3^b*5^c
d:=2^a;
}
H:=[];
for (j:=2;j<=n;j++) {
if (L[j]==0) H:=append(H,j);
}
return H;
}
ou encore en supprimant la variable c :
hamming(n):={
local H,L,a,b,j,d;
L:=makelist(x->x,0,n);
//les nbres de Hamming sont 2^a*3^b*5^c
a:=0;
d:=1;
while (d<=n) {
b:=0;
while (d<=n){
while (d<=n) {
L[d]:=0;
d:=5*d;
}
b:=b+1;
d:=2^a*3^b;
}
a:=a+1;
d:=2^a;
}
H:=[];
for (j:=2;j<=n;j++) {
if (L[j]==0) H:=append(H,j);
}
return H;
}
ou encore en supprimant a,b,c et en preservant la valeur de d avant les while :
hamming(n):={
local H,L,d,j,k;
L:=makelist(x->x,0,n);
//les nbres de Hamming sont 2^a*3^b*5^c
d:=1;
while (d<=n) {
j:=d;
while (j<=n){
k:=j;
while (k<=n) {
L[k]:=0;
k:=5*k;
}
j:=3*j;
}
d:=2*d;
}
H:=[];
for (j:=2;j<=n;j++) {
if (L[j]==0) H:=append(H,j);
}
return H;
}
On tape :
hamming(20)
On obtient :
[2,3,4,5,6,8,9,10,12,15,16,18,20]
On tape :
hamming(40)
On obtient :
[2,3,4,5,6,8,9,10,12,15,16,18,20,24,25,27,30,32,36,40]
Supposons que l’on ait trouvé les premiers éléments de cette suite par
exemple : 2,3,4,5.
L’élément suivant est obtenu en multipliant une des cases
précédentes par 2, 3 ou 5.
Le problème c’est d’avoir les éléments suivants dans l’ordre....
Comment trouver lélément suivant de H:=[2,3,4,5] :
on a déja multiplié H[0]=2 par 2 pour obtenir 4 donc
on peut multiplier H[1]=3 par 2 pour obtenir m=6 ou
multiplier H[0]=2 par 3 pour obtenir p=6 ou
multiplier H[0]=2 par 5 pour obtenir q=10.
L’élément suivant est donc 6=min(6,6,10) et H:=[2,3,4,5,6].
Maintenant, on a déja multiplier
H[0]=2 par 2 et par 3 pour obtenir 4 et 6 et
on a déja multiplier H[1]=3 par 2 pour obtenir 6 donc
donc
on peut multiplier H[2]=4 par 2 pour obtenir m=8 ou
multiplier H[1]=3 par 3 pour obtenir p=9 ou
multiplier H[0]=2 par 5 pour obtenir q=10.
L’élément suivant est donc 8=min(8,9,10) et H:=[2,3,4,5,6,8].
Pour que chaque terme de la suite soit multiplié par 2, par 3 et par 5,
il faut donc pévoir 3 indices :
k0 qui sera l’indice de l’élément qu’il faut multiplier par 2,
k1 qui sera l’indice de l’élément qu’il faut multiplier par 3,
k2 qui sera l’indice de l’élément qu’il faut multiplier par 5.
Cela signifie que :
pour tout r<k0 les 2*H[r] ont déjà été rajoutés,
pour tout r<k1 les 3*H[r] ont déjà été rajoutés,
pour tout r<k2 les 5*H[r] ont déjà été rajoutés,
Naturellement k0≥ k1≥ k2.
Les 3 candidats pour être l’élément suivant sont donc :
2*H[k0], 3*H[k1], 5*H[k2]
l’un de ces éléments est plus petit que les autres et on le rajoute à la
suite. Il faut alors augmenter l’indice correspondant de 1 : par exemple
si c’est 3*H[k1] qui est le minimum il faut augmenter k1 de 1 et
si 3*H[k1]= 5*H[k2] est le minimum, il faut augmenter k1 et
k2 de 1.
hamming(n) va renvoyer les n premiers éléments de la suite de
Hamming.
L’indice j sert simplement à compter les éléments de H.
k est une suite qui contient les indices k0,k1,k2.
On peut initialiser H à [2,3,4,5] donc j à 4,
et k à [1,0,0] (car H[0]=2 a été multiplié par 2,
mais pas par 3, ni par 5) mais cela suppose n>3.
On peut aussi initialiser H à [1], k à [0,0,0]
(H[0]=1 n’a pas été multiplié par 2, ni par 3, ni par 5)
et j à 0 puis enlever 1 de H à la fin car 1
n’est pas un terme de la suite.
Voici la fonction hamming(n) écrite en Xcas pour n>3.
//pour n>3
hamming(n):={
local H,j,k,m,p,q,mi;
H:=[2,3,4,5];
j:=4;
k:=[1,0,0];
while (j<n) {
m:=2*H[k[0]];
p:=3*H[k[1]];
q:=5*H[k[2]];
mi:=min(m,p,q);
H:=append(H,mi);
j:=j+1;
if (mi==m) {k[0]:=k[0]+1};
if (mi==p) {k[1]:=k[1]+1};
if (mi==q) {k[2]:=k[2]+1};
}
return H;
}
Voici la fonction hamming(n) écrite en Xcas pour n>0.
//pour n>0
hamming(n):={
local H,j,k,m,p,q,mi;
H:=[1];
j:=0;
k:=[0,0,0];
while (j<n) {
m:=2*H[k[0]];
p:=3*H[k[1]];
q:=5*H[k[2]];
mi:=min(m,p,q);
H:=append(H,mi);
j:=j+1;
if (mi==m) {k[0]:=k[0]+1};
if (mi==p) {k[1]:=k[1]+1};
if (mi==q) {k[2]:=k[2]+1};
}
return tail(H);
}:;
On tape :
hamming(20)
On obtient :
[2,3,4,5,6,8,9,10,12,15,16,18,20,24,25,27,30,32,36,40]
Le développement diadique de a/b∈ [0;1[ est lécriture de
a/b sous la forme :
a/b=d1/2+d2/22+...+dk/2k avec
dk∈ {0,1}.
diadiquen(a,b,n):={
local d,q,k,p,L;
p:=2;
L:=NULL;
q:=a/b;
pour k de 1 jusque n faire
d:=floor(p*q);
L:=L,d;
q:=q-d/p;
p:=2*p
fpour;
retourne L;
}:;
On tape : diadiquen(3,10,15)diadiques(a,b):={
local d,q,k,p,L,A;
L:=NULL;
A:=NULL;
q:=a/b;
a:=numer(q);
p:=2;
d:=floor(p*q);
repeter
L:=L,d;
si d!=0 alors
A:=A,a;
sinon
A:=A,0;
fsi;
q:=q-d/p;
a:=numer(q);
p:=2*p
d:=floor(p*q);
k:=member(a,[A]);
jusqua k!=0 and d!=0;
retourne [L,mid([L],k-1)];
}:;
On tape : diadiques(3,10)
On veut écrire un entier n ∈ ℕ sous la forme ∑j≥ 1 ajj! avec
0≤ aj<j pour tout j.
Par exemple 43=1· 4!+3· 3!+0· 2!+1· 1!.
| j· j!<N! |
Si n=∑j= 1j=J ajj! avec 0≤ aj<j et aJ≠ 0 on a :
J!≤ n=aJJ!+∑j= 1j=J−1 ajj!<J· J!+∑j= 1j=J−1 j· j!
donc
J!≤ n<(J+1)!
ecritfac(n):={
local j,J,k,L,a;
L:=NULL;
j:=1;
tantque n>=j! faire j:=j+1 ftantque;
J:=j-1;
pour k de J jusque 1 pas -1 faire
a:=iquo(n,k!);
L:=L,a;
n:=irem(n,k!);
fpour;
return L;
}:;
On tape :
ecritfac(43)
Définitions
Lorsque pour p ∈ ℕ, Mp=2p−1 est premier on dit que c’est un nombre
premier de Mersenne.
Un nombre n est parfait si il est égal à la somme de ses diviseurs
propres (1 est compris mais pas n).
Par exemple 6 et 28 sont parfaits car 6=1+2+3 et 28=1+2+4+7+14.
Téorème 1
k est un nombre parfait pair si et seulement si il est de la forme
k= 2n−1(2n−1) avec Mn=2n−1 premier.
Téorème 2
Si Mn=2n−1 est premier, alors n est aussi premier.
La réciproque est fausse (voir le Test de Lucas-Lehmer ci-après),
par exemple, M11 n’est pas premier :
M11=211−1=2047=23*89
Téorème 3
Soient 2 nombres premiers p et q. Si q divise Mp = 2p−1, alors
q=+/−1 (mod8) et il existe k ∈ ℕ tel que q = 2kp + 1.
Téorème 4
Si p un nombre premier vérifiant p = 3 (mod4) alors 2p+1 est un
nombre premier si et seulement si 2p+1 divides Mp.
Téorème 5
Si on fait la somme des chiffres d’un nombre parfait pair différent de 6,
puis la somme des chiffres du résultat et que l’on continue le processus
alors on obtient 1.
Exercice
Écrire un programme qui teste si un nombre n vérifie le théorème 5.
Il faut donc utiliser la fonction revlist(convert(n,base,10)) de
Xcas qui renvoie la liste des chiffres de l’écriture en base 10 de
l’entier n.
On tape :
sumchiffre(n):={
local L,s;
si n==6 alors retourne 1 fsi;
s:=n;
tantque s>9 faire
L:=convert(n,base,10);
s:=sum(L);
ftantque;
si s==1 alors retourne 1;
sinon retourne s;
fsi;
}:;
Test de Lucas-Lehmer
Si p est un nombre premier alors le nombre de Mersenne Mp=2p−1 est
premier si et seulement si 2p−1 divise S(p−1) lorsque S(n) est la suite
définie par S(n+1)=S(n)2−2, et S(1)=4.
Exercice
Écrire le programme correspondant à ce test : on calculera la suite S(n)
modulo 2p−1 pour gagner du temps.
On tape :
Test_LL(p):={
local s,j;
s := 4;
pour j de 2 jusque p-1 faire
s := s^2-2 mod n;
fpour;
si s == 0 alors
return "2^"+string(p)+"-1 est premier";
sinon
return "2^"+string(p)+"-1 est non premier";
fsi;
}:;
On tape :
Test_LL(11213)
On obtient (Evaluation time: 6.43) :
2^11213-1 est premier
On tape :
Test_LL(11351)
On obtient :
2^11351-1 est non premier
Remarque
En janvier 1998, un élève ingénieur a prouvé que Mp était premier
pour p=3021377 (Mp a 909526 chiffres !).
Définitions
Un nombre n est parfait si il est égal à la somme de ses diviseurs
propres (1 est compris mais pas n).
Par exemple 6 et 28 sont parfaits car 6=1+2+3 et 28=1+2+4+7+14.
L’énoncé
Quels sont les nombres parfaits inférieurs à 11000?
Montrer que si 2p−1 est premier alors 2p−1(2p−1) est parfait.
La solution
On utilise l’instruction idivis(n) qui renvoie la liste des diviseurs
de l’entier n et l’instruction sum(L) qui renvoie la somme de la
liste L.
On tape avec les instructions françaises :
parfait(n):={
local j,a,b,L;
L:=NULL;
pour j de 2 jusque n faire
a:=sum(idivis(j))-j;
si a==j alors L:=L,j; fsi;
fpour;
retourne L;
}:;
On tape pour avoir les nombres parfaits inférieur à 11000 :
parfait(11000)
0n obtient :
6,28,496,8128
Si 2p−1 est premier alors les diviseurs de 2p−1(2p−1) sont :
1,(2p−1),2,2(2p−1),22,22(2p−1),..2p−2,2p−2(2p−1),2p−1,2p−1(2p−1).
La somme de ces diviseurs est :
On tape pour avoir cette somme simplifiée et factorisée :
factor(normal(sum(2^k*(1+2^p-1),k=0..p-1)))
0n obtient :
2^p*(2^p -1)
La somme de tous les diviseurs propres de 2p−1(2p−1) est
2p−1(2p−1) donc si 2p−1 est premier 2p−1(2p−1) est parfait.
Euler a montré que tous les nombres parfaits pairs sont de cette forme.
Donc 2p−1(2p−1) est parfait si Mp=2p−1 est premier.
Pour p=2 on a 22−1=3 est premier donc 2*3=6 est parfait.
Pour p=3 on a 23−1=7 est premier donc 4*7=28 est parfait.
Pour p=5 on a 25−1=31 est premier donc 16*31=496 est parfait.
Pour p=7 on a 27−1=127 est premier donc 64*127=8128 est parfait.
Pour p=13 on a 213−1=8191 est premier donc 4096*8191=33550336 est parfait.
Pour p=17 on a 217−1=13107 est premier donc 65536*131071=8589869056 est parfait (il a été découvert en 1588 par Cataldi).
Pour p=19 on a 219−1=524287 est premier donc 262144*524287=137438691328 est parfait (il a été découvert en 1588 par Cataldi).
Puis pour p=31,61,89 on a encore 2p−1 premier ....
En 1936 le Dr Samuel I. Krieger dit que pour p=257 2513−2256 est
parfait (il a 155 chiffres ) malheureusement le nombre 2257−1 n’est pas
premier..... .
On refait donc un programme qui teste si 2p−1 est premier et on en déduit
le nombre parfait correspondant.
parfait2(p):={
local j,a,b,L;
L:=NULL;
pour j de 2 jusque p faire
a:=2^(j-1);
b:=2*a-1;
si isprime(b) alors L:=[L,a*b,j]; fsi;
fpour;
retourne L;
}:;
On tape :
A:=parfait2(1100)
size(A)
On obtient :
14
On tape :
A[13]
On obtient le 14ième nombre parfait :
[2^606*(2^607-1),607]
On tape :
B:=[A]:;
col(B,1)
On obtient la liste des nombres p≤ 1100 tels que 2p−1 soit premier :
[2,3,5,7,13,17,19,31,61,89,107,127,521,607]
Remarque : relation entre les nombres parfaits et les cubes
0n remarque qu’à part 6 chaque nombre parfait est égal à la somme des
cubes de nombres impairs consécutifs:
28=13+33=sum((2*n+1)^3,n=0..1)
496=13+33+53+73=sum((2*n+1)^3,n=0..3)
8128=13+33+53+73+93+113+133+153=sum((2*n+1)^3,n=0..7)
33550336=sum((2*n+1)^3,n=0..63)
8589869056=sum((2*n+1)^3,n=0..255)
137438691328=sum((2*n+1)^3,n=0..511)
0n remarque aussi que l’on fait la somme pour n variant de 0 à :
1=21−1
3=22−1
7=23−1
63=26−1
255=28−1
511=29−1
Question ouverte
Existe-t-il des nombres parfaits impairs ????????????
Ce que l’on sait c’est que si il en existe un alors il est tres grand !
Cete question est certainement le plus vieux problème de mathematiques non
résolu....
L’énoncé
On se propose d’écrire un programme qui donne la suite des couples amiables
dont l’un des nombres est inférieur ou égal à un entier n. Voici les
définitions des nombres parfaits et des nombres amiables :
Définitions
Un nombre n est parfait si il est égal à la somme de ses diviseurs
propres (1 est compris mais pas n).
Deux nombres a et b sont amiables ou amis, si l’un est égal à la
somme des diviseurs propres de l’autre et inversement.
Les nombres parfaits a sont des nombres amiables avec eux mêmes.
La solution
On utilise l’instruction idivis(n) qui renvoie la liste des diviseurs
de l’entier n et l’instruction sum(L) qui renvoie la somme de la
liste L.
Pour ne pas avoir 2 fois le même couple on n’affiche que les couples [j,a]
avec j≤ a.
On tape avec les instructions françaises :
amiable(n):={
local j,a,b,L;
L:=NULL;
pour j de 2 jusque n faire
a:=sum(idivis(j))-j;
b:=sum(idivis(a))-a;
si b==j et j<=a alors L:=L,[j,a]; fsi;
fpour;
retourne L;
}:;
On tape pour avoir les nombres amiable inférieur à 11000 :
amiable(11000)
0n obtient :
[6,6],[28,28],[220,284],[496,496],[1184,1210],[2620,2924],
[5020,5564],[6232,6368],[8128,8128],[10744,10856]
Les nombres parfaits a sont les nombres amiables [a,a].
On se propose d’écrire un programme qui donne les dimensions des
parallélépipèdes rectangles presque parfaits dont les côtés sont
inférieurs ou égaux à un entier n≤ 1000. Voici
la définition d’un parallélépipède rectangle presque parfait :
Définitions
Un parallélépipède rectangle est presque parfait si :
Par exemple, le parallélépipède rectangle de côtés 44 17 240 est
presque parfait.
Attention les 6 permutations de (44 17 240) représentent le même
parallélépipède rectangle.
Si 3 entiers (a,b,c) vérifiant a< b< c représentent un parallélépipède rectangle, pour su’il soit presque parfait il faut que :
Comment tester qu’un nombre p est un carré parfait ?
On peut écrire :
frac(sqrt(p))==0 ou
floor(sqrt(p))^2-p==0
mais cela demande un calcul ! Il est donc préferable d’utiliser la commande
type qui renvoie le type de l’argument. Par exemple :
type(sqrt(4))==integer renvoie 1 et type(sqrt(5))==integer
renvoie 0.
On tape :
parapparfait(n):={
local a,b,c,L;
L:=NULL;
pour a de 1 jusque n faire
pour b de a+1 jusque n faire
si type(sqrt(a^2+b^2))==integer alors
pour c de b+1 jusque n faire
si type(sqrt(a^2+c^2))==integer alors
si type(sqrt(c^2+b^2))==integer alors
L:=L,[a,b,c];
fsi;
fsi;
fpour;
fsi;
fpour;
fpour;
retourne L;
}:;
0n tape : L:=parapparfait(1000)
On obtient (c’est long !):
[44,117,240],[85,132,720],[88,234,480],[132,351,720],
[140,480,693],[160,231,792],[176,468,960],[240,252,275],
[480,504,550],[720,756,825]
On peut modifier le programme pour avoir pour chaque a, une liste provisoire
P qui sera la liste a,b1,b2...bp telle que a2+bj2 soit un
carré. Puis dans cette liste on cherchera les bj et les bk tels que
bj2+bk2 soit un carré. Le triplet [a,bj,bk] répond alors à la
quesstion.
On tape :
paralparfait(n):={
local a,b,c,L,P,j,s,k,b2;
L:=NULL;
pour a de 1 jusque n faire
P:=a;
pour b de a+1 jusque n faire
si type(sqrt(a^2+b^2))==integer alors
P:=P,b;
fsi;
fpour;
s:=size(P)-1;
pour j de 1 jusque s-1 faire
b:=P[j];
b2:=b^2;
pour k de j+1 jusque s faire
c:=P[k];
si type(sqrt(b2+c^2))==integer alors
L:=L,[a,b,c];
fsi;
fpour;
fpour;
fpour;
retourne L;
}:;
0n tape : L:=paralparfait(1000)
On obtient (c’est 2 fois moins long !):
[44,117,240],[85,132,720],[88,234,480],[132,351,720],
[140,480,693],[160,231,792],[176,468,960],[240,252,275],
[480,504,550],[720,756,825]
Remarque
On peut facilement avoir les couples a,b tel que a2+b2 soit un carré.
On tape :
sommecarre(n):={
local a,b,L,P;
L:=NULL;
pour a de 1 jusque n faire
P:=a;
pour b de a+1 jusque n faire
si type(sqrt(a^2+b^2))==integer alors
P:=P,b;
fsi;
fpour;
si size(P)>1 alors L:=L,[P];fsi;
fpour;
retourne L;
}:;
On tape : sommecarre(100)
On obtient :
[3,4],[5,12],[6,8],[7,24],[8,15],[9,12,40],[10,24],
[11,60],[12,16,35],[13,84],[14,48],[15,20,36],
[16,30,63],[18,24,80],[20,21,48,99],[21,28,72],
[24,32,45,70],[25,60],[27,36],[28,45,96],[30,40,72],
[32,60],[33,44,56],[35,84],[36,48,77],[39,52,80],
[40,42,75,96],[42,56],[45,60],[48,55,64,90],[51,68],
[54,72],[56,90],[57,76],[60,63,80,91],[63,84],[65,72],
[66,88],[69,92],[72,96],[75,100],[80,84]
Par exemple, on voit que :
202+152 est un carré : c’est 252,
202+212 est un carré : c’est 292,
202+482 est un carré : c’est 522,
202+992 est un carré : c’est 1012.
ou encore
602+112 est un carré : c’est 612,
602+252 est un carré : c’est 652,
602+322 est un carré : c’est 682,
602+452 est un carré : c’est 752,
602+632 est un carré : c’est 872,
602+802 est un carré : c’est 1002.
602+912 est un carré : c’est 1092.
On peut aussi en déduire que :
602+1442 est un carré : c’est 1562 (car 152+362=392).
602+1752 est un carré : c’est 1852 (car 122+352=372).
602+2972 est un carré : c’est 3032.(car 202+992=1012).
Mais si on veut tous les nombres b≤ 300 tels que n2+b2 soit un
carré il est préférable d’écrire le programme :
n2plusb2(n,N):= {
local b,P;
P:=n;
pour b de 1 jusque N faire
si type(sqrt(n^2+b^2))==integer alors
P:=P,b;
fsi;
fpour ;
P;
}:;
On tape : n2plusb2(20,1000)
On obtient :
20,15,21,48,99
On tape : n2plusb2(60,300)
On obtient :
60,11,25,32,45,63,80,91,144,175,221,297
seul 602+2212=2292 n’avait pas été trouvé précédemment car 229
est un nombre premier !
On tape : n2plusb2(60,1000)
On obtient :
60,11,25,32,45,63,80,91,144,175,221,297,448,899
On se propose d’écrire un programme qui donne la suite des nombres heureux inférieurs ou égaux à un entier n. Voici un algorithme définissant cette suite :
Par exemple :
après la première étape on a : 2,3,5,7,9,11,13,15,17...
après la deuxième étape on a : 2,3,5,7,11,17...
Ce programme ressemble au crible d’Eratosthène, mais si m est le
nombre que l’on vient d’entourer et qu’il est d’indice p, on supprime les
nombres d’indices p+m,p+2m...p+km mais dans la liste tab modifiée
et non les multiples du nombre m.
On tape avec les instructions françaises :
heureux(n):={
local tab,heur,m,j,p,k;
tab:=j$(j=2..n);
tab:=concat([0,0],[tab]);
heur:=[];
p:=2;
tantque (p<=n) faire
m:=p;
k:=0;
pour j de p+1 jusque n faire
si tab[j]!=0 alors k:=k+1; fsi;
si irem(k,m)==0 alors tab[j]:=0 fsi;
fpour;
p:=p+1;
si p<=n alors
tantque tab[p]==0 and p<n faire p:=p+1 ftantque;
si p==n and tab[p]==0 alors p:=n+1;fsi;
fsi;
ftantque;
pour p de 2 jusque n faire
si (tab[p]!=0) alors
heur:=append(heur,p);
fsi;
fpour;
retourne(heur);
}:;
Dans ce programme on peut se passer de la liste heur : il suffit de
supprimer la dernière instruction pour et de mettre :
retourne remove(x->x==0,tab); à la place de retourne heur
On tape : heureux(100)
On obtient :
[2,3,5,7,11,13,17,23,25,29,37,41,43,47,53,61,67,71,77,83,89,91,97]
On peut aussi et ce sera plus rapide, modifier la liste tab au fur et
à mesure en supprimant à chaque étape les valeurs barrées c’est à
dire les valeurs mises à 0 en utilisant l’instruction remove et en
mettant au fur et à mesure les nombres heureux dans heur.
On tape avec les instructions françaises :
//renvoie la liste des nombres heureux<=n
heureux2(n):={
local tab,heur,m,j,k,s;
tab:=[j$(j=2..n)];
heur:=[];
s:=dim(tab);
k:=0;
tantque (s>0) faire
j:=0;
m:=tab[0];
heur[k]:=m;
tantque j<s faire
tab[j]:=0;
j:=j+m;
ftantque;
tab:=remove(x->x==0,tab);
s:=dim(tab);
k:=k+1;
ftantque;
retourne(heur);
}:;
On tape : heureux2(100)
On obtient :
[2,3,5,7,11,13,17,23,25,29,37,41,43,47,53,61,67,71,77,
83,89,91,97]
Résoudre l’équation de Pell c’est trouver les plus petits entiers x,y qui
sont solutions de x2−n*y2=1 lorsque n est un entier.
Euler à montré que l’on pouvait résoudre cette équation à l’aide du
développement en fraction continue de √n (par exemple dfc(n,20)).
Supposons que le développement en fraction continue de √n soit de
période k. On a :
Soit le développement en fraction continue de √n :
√n=[a0,a1,....ak,xk]
Soient :
| =[a0,a1,....ak] |
| xk= |
|
On a les relations :
| A2=0, A1=1, Ak=ak Ak−1+Ak−2 |
| B2=1, B1=0, Bk=ak Bk−1+Bk−2 |
| ak=floor( |
| ) |
Puisque xk+1=1/(xk−ak) on a :
| P0=0, Pk+1=akQk−Pk |
| Q0=1, Qk+1=ak(Pk−Pk−1)+Qk−1 |
Donc
| − |
| =(−1)k+1 |
|
On a :
| √ |
| = |
| = |
|
Donc
| QkAk−2+Pk Ak−1=n Bk−1 |
| QkBk−2+Pk Bk−1=Ak−1 |
On a donc
| (Ak−2Bk−1−Ak−1Bk−2)Qk=nBk−12−Ak−12=(−1)k−1Qk |
Si (Pn +√n)/Qn est le n-ième quotient du développement en
fraction continue de √n alors si Qh= Qh−1
(resp Ph= Ph−1) on a k=2h−1 (resp k=2h−2).
On en déduit donc la valeur k de la période.
La plus petite solution de x2 − ny2 =1 est donnée par :
Ak−1 + Bk−1√n où An/Bn est la n-ième fraction convergeant
vers √n.
Remarque
Soit n un entier. Si x0,y0 sont solutions de x2−n*y2=1 alors
xk,yk sont d’autres solutions grace à la formule :
| xk+yk | √ |
| =(x0+y0 | √ |
| )k |
En effet, par récurrence si on a xk+yk√n=(x0+y0√n)k et
(xk,yk) solution de x2−ny2=1 alors :
xk+1+yk+1√n=(x0+y0√n)*(xk+yk√n) donc
xk+1=x0xk+ny0yk et
yk+1=x0yk+y0xk donc
xk+12=(x0xk+ny0yk)2=x02xk2+n2y02yk2+2nx0xky0yk=
x02xk2+(1+x02)(1+xk2)+2nx0xky0yk=2x02xk2+x02+1+xk2+2nx0xky0yk
nyk+12=n(x0yk+y0xk)2=nx02yk2+ny02xk2+2nx0yky0xk=
=x02(1+xk2)+(1+x02)xk2+2nx0yky0xk=2x02xk2+x02+xk2
donc
| xk+12−nyk+12=1 |
Le programme ci dessous trouve les plus petits entiers A,B qui sont solutions
de A2−n*B2=1 lorsque n est entier qui n’est pas un carré parfait.
Les différentes valeurs de a sont le développement en fraction continue
de √n.
Ap/Bp sont les réduites de rang p (Ap/Bp=[a0,...ap])
On a Pk et Qk qui sont tels que:
√n=[a−0,a−1,...ak−1+Qk/(√n+Pk)]
Pell(n):={
local A,B,P,Q,R,a,sn,AA,BB,NA,NB;
if (type(n)!=DOM_INT) {return "erreur"};
if (round(sqrt(n))^2==n) {return "erreur"};
R:=0;
Q:=1;
P:=0;
sn:=floor(sqrt(n));
a:=sn;
AA:=1;A:=a;
BB:=0;B:=1;
print(a,P,Q,R,A,B);
while (A^2-n*B^2!=1) {
P:=sn-R;
Q:=(n-P^2)/Q;
a:=floor((P+sn)/Q);
R:=irem(P+sn,Q);
NA:=a*A+AA;
NB:=a*B+BB;
AA:=A;
BB:=B;
A:=NA;
B:=NB;
print(a,P,Q,R,A,B);
}
return (A,B);
}
:;
On tape :
Pell(13)
On obtient :
649,180
En effet : 6492−13*1802=1
On tape :
Pell(43)
On obtient :
3482,531
En effet : 34822−43*5312=1